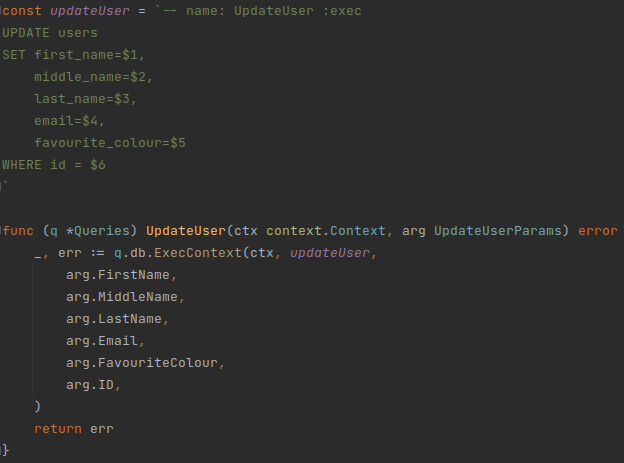
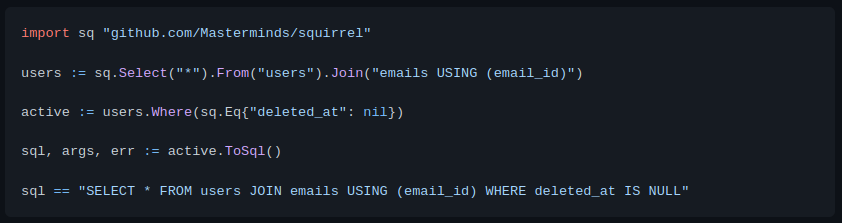
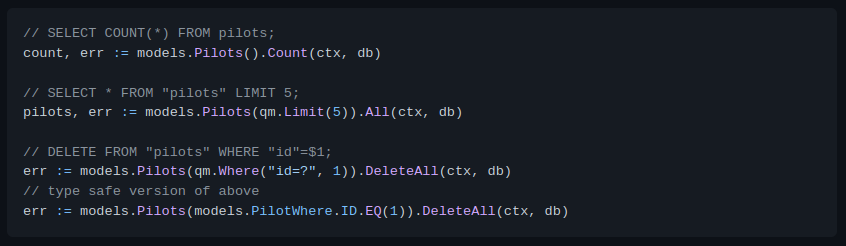
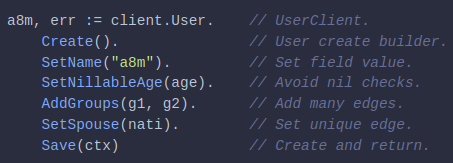
During development, we follow a process and have many tools including functional tests (unit, integration, end-to-end), static analyzer, performance regression tests, and others before we ship to production. In spite of developers best effort, bugs do occur in production. Typical tools we have during development may not be applicable to a production setting. What we need is some visibility on our program’s internal state and how it behaves in production. For example, error logs can tell what is going on and include what user request looks like. An endpoint which is slow will need to be looked at, and it will be great if we can find out which one, and pinpoint exactly where the offending part of a codebase is. These data—or signals—are important to give us insight on what is going on with our applications. For the rest of this post, we will look at available tools to give us this visibility and help us solve this problem.
There are many tools, a crowded one, that provides visibility into not only how a program behaves, but can also report errors while a program is running in production. You may have heard of the term APM or application performance monitoring solutions like Splunk, Datadog, Amazon X-Ray, Sentry.io, ELK stack, and many others that provide complete (partial in some) end-to-end solution to peek under the hood and provide tools to developers to understand a program’s behaviour. These solutions work great. But sometimes we want the flexibility of switching to another vendor. It may be because we want features other vendor have, or it may be because of cost-saving. When we try to adopt one of these solutions, you might find it hard to migrate because of extensive changes needed to be done throughout a codebase, thus feeling locked into one ecosystem.
Thus came OpenTelemetry. It merges the efforts of OpenCensus and OpenTracing in the yesteryear into a single standard anyone can adopt so switching between vendors becomes easier. The term OpenTelemetry in this post encompasses the APIs, SDKs and tools to make up this ecosystem. Over the years, to my surprise, OpenTelemetry is being adopted by heavy hitters including the companies I mentioned above, as well as countless startups in the industry. This is great because when it becomes easy to switch, there is a greater incentive for these vendors to provide a better service and this only benefits developers and your company stakeholders. This is the promise of a vendor-neutral approach championed by cncf.io to ensure innovations are accessible for everyone.
Today, OpenTelemetry has advanced enough that I am comfortable at recommending them to any software programmers. OpenTelemetry has come a long way (and evolved over the years) so in this post, we will give a basic explanation of what OpenTelemetry is and an overview of how its observability signals work under the hood. Then we talk about how its collector tool works and how it helps in achieving vendor-neutrality.
Before we go deeper into implementation, we need to know what we are measuring or collecting. In OpenTelemetry world, these are called signals which includes metrics, tracing, and logs. These signals are the three pillars of OpenTelemetry.
Figure 1: Greek pillars are what I imagine every time I hear the term three pillars of observability.
Logs are basically the printf or console.log() to display some internal messages or state of a program. This is what developers are most familiar with. It provides invaluable information at debugging.
Metrics represents aggregation of measurements of your system. For example, it can measure how big is the traffic to your site and its latency. These are useful indications to find out how your system performs. The measurement can be drilled down to each endpoint. So your system could have a 100% uptime by looking at your /ping endpoint, but it does not tell how each endpoint performs. Other than performance, you might be interested to know other measurements like the current total active logged-in users, or the number of user registrations in the past 24 hours.
Tracing may be the least understood tool as it is a relatively newer signal tool. Being able to pinpoint where exactly an error is happening is great—something that logs can do—but arriving to that subsystem can originate from multiple places (maybe from a different microservice). Moreover, an error can be unique to a request, so being able to trace the whole lifecycle of the request is an invaluable tool to find how the error came to be.
These are the central signals that we will dive into deeply. There is a fourth signal called profiling. Profiling has been with us for decades, and it is an invaluable tool during development that gives us means to see how much RAM and CPU cycles a particular function uses down to the line number. Profiling in this context refers to having these data live in a production setting (just like the other three signals), and across microservices! For now, profiling is in an infancy state, so we will focus on the other three signals.
Visualisation
Before diving deeper into the signals, it would be great to see if we can visualise what the end product could look like. The screenshot below is an example of an observability dashboard we can have. It gives us a quick glance on important information such as how our endpoints are doing, what logs are being printed, and some hardware statistics.
Figure 2: Single pane of view to observability.
Now we will look into each of the pillars, so let us start with the most understood signal, namely logging.
Logging
When you have a program deployed on a single server, it is easy to view the logs by simply SSH-ing into the server and navigate into the logs directory. You may need some shell script skills in order to find and filter relevant lines pertaining to errors you are interested with. The problem comes when you are also deploying your program to multiple servers. Now you need to SSH to multiple servers in order to find the errors you are looking for. What’s worse is when you have multiple microservices, and you need to navigate to all of them just to find the error lines you want.
Figure 3: Have you ever missed the error lines you are interested with in spite of your shell script skills?
An easy solution is to simply send all of these logs into a central server. There are two ways of doing this; either the program pushes these logs to a central server, or you have another process that does the collecting and batching to send these logs. The second approach is what is recommended in the 12-factor app. We treat logs as a stream of data and log them to stdout, to be pushed to another place where we can tail and filter as needed. The responsibility of managing logs is handed over to another program. To push the logs, the industry standard is by using fluentd but there are other tools like its rewrite called Fluent Bit, otel-collector, logstash, and Promtail. Since this post is about OpenTelemetry, we will look at its tool called otel-collector.
Figure 4: No matter where logs are emitted, they can be channelled to otel-collector.
In the diagram above, Java spring boot app does not save the logs into a file. Instead, we have an option of an easy auto-instrumentation called OpenTelemetry javaagent SDK that automatically sends the logs to otel-collector.
A containerised application like the python Django application can have its logs tailed to be sent to otel-collector too. In reality, logs in containerised apps live in a place like /var/lib/docker/containers/<container_id>/*.log anyway. So, PHP logs like laravel which saves logs into files can be sent the same way to otel-collector.
Like many tools, otel-collector is flexible with where it can retrieve logs from. The log collection is not limited to API applications. Syslog and logs from the database can also be emitted to otel-collector.
This single otel-collector accepts a standardised API for logs. This means any vendor that can support OpenTelemetry can read your log output.
Figure 5: Choose between any logging backend you like as long as they support otlp format.
Now that you have all logs in one place, you can search, filter by application or log level easily. OpenTelemetry’s solution automatically associates log entries with its origin which makes this an easy task.
Below screenshot shows a snippet of what a log aggregator like Loki can do. Here, I picked logs only for Laravel that have the word ‘ErrorException’ in it, formatted as json and only where the log level is more than 200. This query language is not standardised yet, but it already looks more readable than writing shell scripts with tail, awk, and grep.
Figure 6: Great user interface that allows searching using a readable query language.
Filtering the logs based on origin is not the only task OpenTelemetry supports. You will also be interested in finding out all logs from a particular request. This request can have a unique identifier, and we can associate this unique key to all logs in this particular request. The code below has a unique string (bcdf53g) right after log level being associated to a single request lifecycle for retrieving a list of authors from the database.
...
[2023-11-16 13:15:48] INFO bcdf53g listing authors
[2023-11-16 13:15:48] INFO e6c8af8 listing books
[2023-11-16 13:15:50] INFO bcdf53g retrieiving authors from database
[2023-11-16 13:15:51] ERROR bcdf53g database error ["[object] (Illuminate\\Database\\QueryException(code: 1045):
...
Now you can filter the logs for that particular request to get a better understanding of how the error came about.
{job="laravel"} |= bcdf53g
This returns only relevant log lines to you and eliminates the noise you do not care about.
...
[2023-11-16 13:15:48] INFO bcdf53g listing authors
[2023-11-16 13:15:50] INFO bcdf53g retrieiving authors from database
[2023-11-16 13:15:51] ERROR bcdf53g database error ["[object] (Illuminate\\Database\\QueryException(code: 1045):
...
More details about this unique key is covered in the tracing section. Also note that the logs do not always have to be in JSON format. The normal log line format shown above is still fine and most vendors provide the ability to filter and search this kind of format.
~~
Before moving on to the next signal, there is one thing of note which must be mentioned which is its SDK availability.
The OpenTelemetry SDK is fantastic if its SDK exists for your programming language. Recently, logs SDK has reached its stable 1.0 version and is generally available for most of the major programming languages.
But there are some glaring omission in this table. Considering many of observability programs are written in Go, its logs SDK for this language is missing. To make matter worse, there is no easy auto-instrumentation like Java is for Go. There are solutions to overcome this using eBPF like what Odigos and Grafana Beyla are doing which are worth keeping an eye on. Python is another major programming language which is at ‘Experimental’ stage. Nevertheless, there is always an alternative such as using a log forwarder like fluentd or Promtail. You might want to ensure the tools you use is otlp-compatible so that you do not have to re-instrument your code base in the future.
Figure 8: Alternative pathway for pushing logs into your backend using promtail.
Metrics
According to the 4 Golden Signals for monitoring systems, we measure traffic, latency, errors and saturation. For metrics, we care about RED method which are Rate, Errors, and Duration.
Just like logging where logs are channelled to a central place, metrics data are also aggregated through otel-collector and then exposed as an endpoint. By default, metrics data are accessed from otel-collector through http://localhost:8889/metrics. This is the endpoint that a vendor like Prometheus uses to scrape metrics data at a regular interval. Let us have a look at what these metrics data look like.
Let us make a single request to a freshly instrumented application. For example:
curl -v http://localhost:3080/uuid
Then visit the endpoint exposed by otel-collector at http://localhost:8889/metrics to view metrics data. The data being returned is in plaintext (text/plain) with a certain format.
Figure 9: Raw metrics data collected by otel-collector.
For now, we are interested in finding out the request counter. So do a search with Ctrl+F for the metric name called http_server_duration_milliseconds_count.
Inside this metric, it contains several labels in a key="value" format separated by commas. It tells us that this metric records the /uuid endpoint for a GET request. It also tells us this is for a job called java_api. This job label is important because we could have the same metric name in other APIs, so we need a way to differentiate this data. At the end of the line, we have got a value of 1. Try to re-run the api call once more, and watch how this value changes.
curl -v http://localhost:3080/uuid
Refresh and look for the same metric for /uuid endpoint. You will see that the value has changed.
http_server_duration_milliseconds_count{...cut for brevity...} 2
Notice that at the end of the line, the value has changed from 1 to 2.
So how does this measure the rate? A rate is simply a measurement of change that occurs over time. There was a lag that happened between the first time you called /uuid end point and the second. Prometheus uses this duration and collects the value in order to find out the rate. Easy math!
Figure 10: Formula to finding out the rate is simply the delta over time.
~~
What about latency? The amount of time it took to complete a request is stored into buckets. To understand this, let us take it step-by-step. For this api, Prometheus stores the latency in histograms. Let us construct a hypothetical one:
Figure 11: Hypothetical cumulative histogram that stores request duration into buckets.
If a request took 97 milliseconds, it will be placed inside the fourth bar from the left because it was between 25 and 100. So the count increased for this bar labelled as ‘100’.
Anything lower than five milliseconds will be placed in the ‘5’ bucket. On the other extreme, any requests that take longer than three seconds get placed in the infinity(‘inf’) bucket.
Take a look back at the http://localhost:8889/metrics endpoint. I deleted many labels keeping only the relevant ones, so it is easier to see:
From the raw data above we can see that there is one request that took between 5 and 10 milliseconds. And another between 100ms and 250ms. What is strange is that there are values for bars such as ‘250’ and ‘500’. Value for bar ‘10’ is one because when a request latency is between 5ms and 10ms. The bar for ‘250’ is also one because it is also true that that request is less than or equal (le) to 10(!). The same reasoning applies to bar ‘500’. This type of histogram which is used by Prometheus is called cumulative and the ’le’ labels were predefined or fixed-boundaries.
This is such a simple example but should give you enough intuition on how they store data into histogram buckets.
~~
Now that we understand how Prometheus calculates rates and latency, let us visualise these. But first we need to use some query languages to translate what we want into something Prometheus understands. This query language is called PromQL.
Going into Prometheus’ web UI at http://localhost:9090, type in the following PromQL query. We re-use the same metric which is http_server_duration_milliseconds_count. Then we wrap the whole metric with a special function called rate(), and we want a moving or sliding calculation over one minute.
Using PromQL like above, we get fancy stuff like line charts for latency and throughput. You can view the line chart by clicking on the ‘Graph’ tab. But visualising from the provided Grafana dashboard looks nicer.
Figure 12: Line charts showing latency and throughput for /uuid endpoint.
On the top half of the screenshot above, it shows latency for /uuid endpoint. Green line shows a 200 HTTP status response while the yellow line shows a 500 HTTP status response. Success response stays below 1 millisecond while error response is around 4 milliseconds. The lines can be hovered to see more details.
On the bottom half, it shows throughput or the rate/second. The graph shows an increasing throughput over time which reflects our synthetic load generator slowly increasing the number of users.
Prometheus support in your architecture
Web applications are not the only thing it can measure. Your managed database may already come with Prometheus support. Typically, such metrics are exposed by your service with /metrics endpoint so check out the documentation of your software of choice and you might be able to play with Prometheus right now.
Caveat
Metrics are great but the way it collects them produces a downside. If you look closely in both rate and latency calculations, there is always a mismatch between when something has happened and when Prometheus recorded these events. This is just the nature of Prometheus because it aggregates the states at a certain period in time. It does not record every single event like InfluxDB does. On the flip side, storing metrics data becomes cheap.
More
We have only talked about one type of measurement which is histogram. But it can also measure other types.
Counters can be used to record increasing amounts of data points. For example, counting site visits.
Gauge can be used for data points that can continuously increase and decrease. For example, CPU or RAM usage.
Tracing
As mentioned at the start of this post, knowing where an error occurred is great but what is better is knowing the path it took to arrive at the particular line of code. If you think this sounds like a stack trace, it is close! A stack trace shows functions that were called to arrive at a specific offending code. What is so special about tracing in observability? You are not limited to a single program, but you have the ability to follow a request flow across all of your microservices. This is called distributed tracing.
But first, let us start with a basic tracing and visualise using a time axis below through Grafana UI.
Figure 13: Name and duration of twelve spans for this single trace of this request.
There are a lot going on but let us focus on what’s important. Every single trace (a unique request), has a random identifier represented by its hex value called trace ID. In the diagram above, it is 385cfe8270777be20b840671bc246e50. This trace ID is randomly generated for each request by the OpenTelemetry library.
Under the ‘Trace’ section, we see a chart with twelve horizontal dual-coloured bar graphs. These bars are called spans, and they belong to the single trace above. A span can mean anything, but typically we create one span for a one unit of work. The span variable you see in the code block below was created for the ListUUID() function. Using a manual instrumentation approach, we have to manually write a code to create a span, let the program do the work, then call span.End() before the function exits to actually emit the span to the otel-collector.
// api.go
func (s *Server) ListUUID(w http.ResponseWriter, r *http.Request) {
tracer := otel.Tracer("")
ctx, span := tracer.Start(r.Context(), "ListUUID")
defer span.End()
// do the work
A span can belong to another span. In the trace graph above, we created a child span called “call microservice” for “ListUUID”. And because we performed an HTTP call to the java api, a span is automatically created for us.
Once the request went into the java API, all spans were created automatically thanks to auto-instrumentation. We can see the functions that were called, as well as any SQL queries that were made.
Each span not only shows parent-child relationship, but also the duration. This is invaluable to knowing possible bottlenecks across all of your microservices. We can see the majority of time was spent on the span called ‘SELECT db.uuid’ which took 21.98 milliseconds out of 23.44 milliseconds total of this request. That span can be clicked to display more details in the expanded view.
Figure 14: Each span can be clicked to reveal more information.
Here we see several attributes including the database query. At the bottom, we see this span’s identifier which is 7df1eaa514d8605d.
Thanks to visualisation of the spans, it is easy to spot which part of the code took the most time.
Drilling down which part of the code is slow is great, but 23.4 millisecond response time for a user-facing request is not something to be concerned with. The user interface allows us to filter slow requests by using the search button. For example, we can put a minimum duration of 500 milliseconds into the search filter form.
Figure 15: Spans can be filtered to your criteria.
This way, we can catch slow requests, and have the ability to see the breakdown of which part of the code took most of the time.
Automatic Instrumentation
So tracing is great. But to manually insert instrumentation code into each function can be tedious. We did manual instrumentation for the Go api which was fine because we did not have to do many. Fortunately, code can be instrumented automatically without touching your codebase in several languages.
In languages where it depends on an interpreter (like Python) or Java VM (like this java demo API), bytecode can be injected to capture these OpenTelemetry signals. For example in Java, simply supply a path to a Java Agent, and set any config from either the startup command line or environment variable to your existing codebase.
Programs that compile into binaries are harder. In this case, eBPF-based solution like Odigos and Beyla can be used.
Sampling Traces
Unlike Prometheus where it aggregates records, we could store every single trace into the storage. Storing all of them will likely blow your storage limits. You will find that many individual traces are nearly identical. For that reason, you might want to sample the traces, say, only store ten percent of the traces. However, be careful of this technique because the trace you are interested in might lose its parent context because it selects traces at random. For that reason, trace SDK provides several sampling rules (https://opentelemetry.io/docs/concepts/sdk-configuration/general-sdk-configuration/#otel_traces_sampler). Sampling this way still means it is possible to miss an error happening in the system.
Distributed Tracing
As demonstrated with the demo repository, I have shown distributed tracing across two microservices. To achieve this, each service must be instrumented with OpenTelemetry SDK. Then when making a call to another microservice, span context is attached to outgoing requests for the receiving end to extract and consume.
Implementing OpenTelemetry into a program is termed as instrumenting. It can be done either manually, or automatically. Manually means writing lines of code into the functions to retrieve and emit both traces and spans.
Automatic instrumentation means either not touching the code at all or very minimal depending on the language. Approaches include using eBPF, or through runtime like Java’s approach to using JavaAgent, or an extension for php.
In either case, vendor-neutrality means your application only needs to be instrumented once using an open standard SDK. You may change vendors but your codebase stays untouched. All these signals are funnelled into a single collector before they are dispersed to OpenTelemetry-compatible destinations. Thanks to this SDK, you have fewer things to worry about when moving to another vendor.
As this is an open standard, otel-collector is not the only tool available out there. Alternatives like grafana agent exists too.
Now that we have OpenTelemetry signals in otlp format, any vendor that understands this protocol can be used. You have a growing choice of vendors at your disposal, open source or commercial, including Splunk, Grafana, SigNoz, Elasticsearch, Honeycomb, Lightstep, DataDog and many others.
Figure 16: A single collector to forward observability signals to any vendor you like.
Having a single component does not look good architecture-wise because it can become a bottleneck. In this context, it only means standardising the format so that anyone can write and read from it.
One deployment strategy is you can have multiple instances of otel-collector to scale it horizontally by putting a load balancer in front of it. Another popular approach is to have one otel-collector sit next to each of your programs like a sidecar. You can even put a queue in between otel-collector and vendors to handle load spikes.
Otel-Collector Components
As everything goes through otel-collector, let us talk one layer deeper about its components namely receivers, processors, exporters, and pipelines.
Receivers are how an otel-collector receives any observability signals. In the config file, we define a receiver called otlp using both gRPC and http as its protocol. By default, otel-collector listens at port 4317 and 4318 for HTTP and gRPC respectively.
Processors are how data is transformed inside the collector before being sent out. You can optionally batch them and have some memory limit. Full list of processors are in https://github.com/open-telemetry/opentelemetry-collector/tree/main/processor and contrib repo. Rate limiter is not in one of the processors so at a higher scale. A third party queue that sits in between otel-collector and vendors might be needed to alleviate possible bottlenecks.
Exporters are how we define where to send these signals to. Here we have three. Metrics are being sent to Prometheus which is fast becoming the de-facto industry standard for metrics. Tracing, which is labelled as otlp will be sent to Jaeger while logs and sent to a URL. As you can see, switching your backend from one to another is as easy as swapping a new exporter(vendor) into this file.
If you want to emit to multiple vendors, that can be done too. Simply add a suffix preceded with a slash (like /2) to it. Below, we can choose to send logs to both loki and dataprepper using ‘otlp/logs’.
Metrics data are exposed as an endpoint at otel-collector:8889/metrics. For vendors who have OpenTelemetry protocol (otlp) support, these metrics can be pushed straight from otel-collector. For example, metrics can be pushed straight to Prometheus using http://prometheus:9090/otlp/v1/metrics endpoint.
Pipeline is the binding component that defines how data flows from one to another. Each of trace, metrics, and logs describes where to pull data, any processing needs to be done, and where to put the data to.
Lastly, Extensions can be applied to collect otel-collector’s performance. Examples are listed in the repository including profiling, zPages, and others.
Having a single component that funnels data into otel-collector is great because when you want to switch to another log vendor, you can just simply add the vendor name into the logs’ exporters array in this configuration file.
Vendor Neutrality
A great deal of effort has been made to ensure vendor-neutrality in terms of instrumentation and OpenTelemetry protocol support. A standard SDK means you can instrument your code once, be that automatic or manual. Vendors supporting otlp means you can pick another vendor of your choosing easily by adding or swapping in your yaml file. The other two important parts to achieving vendor-neutrality are dashboards and alerting. Note that these components are not part of OpenTelemetry, but it is important to discuss this part of the ecosystem as a whole.
Both Prometheus and Jaeger have their own UI at http://localhost:9090 and http://localhost:16686 respectively. However, it is easier to have all information in one screen rather than shuffling between different tabs. Grafana makes this easy, and it comes with a lot of bells and whistles too. It gives the information I want, and they look great. However, are those visualisations portable if I want to switch to another vendor?
Take this case with Prometheus. Data visualisation is done using its query language called PromQL. While it may be the dominant metrics solution, competing vendor might have a different idea on the DSL to create visualisations. The same goes with querying logs—there isn’t a standard yet. For this, a working group to create a standardised, unified language has been started.
Second concern is alerting. It is crucial because when an issue arises in your application—latency for a specific endpoint passes certain threshold—it needs to be acted upon. You can measure response times using metrics like Mean Time to Acknowledge (MTTA), Mean Time to Resolve(MTTR) and others can be crucial for your service level agreement (SLA). Performing within SLA margins makes happy customers and pockets.
Alerting rules you have made in one vendor might not be portable to another since a standard does not exist.
Conclusion
In this post, we have learned about three important OpenTelemetry signals which are logs, metrics, and tracing. OpenTelemetry SDKs made it easy to instrument your application in your favourite language. Then we talked about otel-collector which receives, transforms and emits these signals through a standard API. Vendors that support OpenTelemetry protocol give us the freedom to pick and choose however we like without concern of re-instrumenting our codebase.
The approach OpenTelemetry is taking achieves vendor-neutrality which benefits everyone. For developers, it takes out the headache of re-coding. For business owners, it can be a cost-saving measure. For vendors, rising popularity means more potential customers come into this observability space.
For many years, OpenTelemetry project has been the second most active CNCF project right behind kubernetes amongst hundreds. It is maturing fast and it is great to see the industry working together for the common good.
Learn the ins and outs of deploying a Nuxt frontend, Go api and Postgres database in kubernetes.
This is the second part of the kubernetes(k8s) series where we will focus on deploying three applications inside a k8s cluster namely a Postgres database, a Go API server, and a Nuxt frontend single-page-application (SPA).
Along the way, we will learn about typical k8s objects including Deployment, Service, PersistentVolume, Secret, but also related stuff like port-forwarding, authorization, building container images, and many others. Just like the first part, this post is also going to be elaborate containing many details because k8s is a behemoth, and I think it is a good idea to look a little bit under the hood to get a better understanding of how all the pieces work together. What we will do is to simply break it down into smaller parts, and you will see that using a handful of yaml files were enough to easily deploy applications on k8s.
Circling back to the applications, we are going to deploy three items:
A frontend written in Nuxt 3 that you will see and interact with
A database using Postgres that will store our data
A backend api server written in Go
The frontend will be a simple interface where it will list the latest ten UUID items which are stored from a database. We will add an ‘add’ button where a new random UUID is generated and stored into the database. Once that is done, it will do another api call to retrieve the latest UUIDs.
This is what it’ll look like
Figure 1: Demonstration of the final product
Since all three applications are going to live inside k8s, we need a way to access them. To expose the applications, we will port-forward a couple of applications to our local computer. Firstly, the frontend needs to be port-forwarded so that we can access it using the browser from local the computer. The frontend needs access to the api, so we will port-forward that too. Database does not need to be port forwarded because it is only going to interact with the api within the cluster. There is an important step regarding the address we need to use for api to access the database which we will see later.
Figure 2: Overall architecture of the applications
Finally, the backend api server acts as an intermediary between the frontend and the database. Although its purpose is simple, we need to think about from where will this api read configuration settings. When deploying a new update to the api, we want to ensure in-progress requests not be cancelled out, so we need a graceful way of shutting down the program. By extension, k8s needs to know if the api is running, otherwise it needs to route incoming requests to another Pod. If there are any database schema changes, that needs to be applied as well. As you can see, there are many things need to be considered and for that, some principles of 12-factor apps are going to be applied. Lots of questions need to answered, and we will look at designing such application.
~~
To follow along this post, these are the three repositories you may clone and play with. Devops repo is intentionally separate from api and web with the idea that cluster admin manages k8s side and database, while full-stack developers only concern with api and frontend. This blog post will assume you are part of a devops team. Sections with a fullstack engineer role will be made known in the code block commented with ### Run by user dev007..
We need a database that can persist our random UUID data so our api can access and store them. For that, let us deploy a postgres database in the k8s cluster. There are several k8s objects we require for this setup. We will see that k8s tends to use the terms ‘object’ and ‘resource’ interchangeably, as will I. First up is configuration.
Configuration
Before creating a database, we need to set credentials as variables such as username, password, and database name. There are various ways to do this but the simplest is to simply set them as environment variables — some might argue this is a best practice. Anyhow, let us look at a first approach, which is a ConfigMap.
The following is a k8s object called ConfigMap named as ‘db-credentials’. This is the name to identify this particular ConfigMap object. You will see a lot of yaml files from now on. These files are written in a declarative way that states what we want the final picture to look like — we declare that we are setting my_db as the database name, etc…
# /k8s-devops/db/configmap.yamlapiVersion: v1
kind: ConfigMap
metadata:
name: db-credentials
labels:
app: postgresdb
data:
POSTGRES_DB: "my_db"POSTGRES_USER: "user"POSTGRES_PASSWORD: "Password"# sensitive information should not be left unencrypted!PGDATA: "/var/lib/postgresql/data"
As you can see there is a glaring issue with this because the database password is in plain sight so this file cannot be committed to a public repository.
We can use another k8s object called Secret. Any sensitive data including passwords, a token, or a key can be stored in this Secret object. So we remove POSTGRES_PASSWORD from ConfigMap, and we use a Secret object instead as follows:
This looks much better because now you do not see the sensitive data in plain sight. However, the value is actually a base64 encoded password using echo -n "Password" | base64 command. That means, anyone with access to the cluster with the right authorization will be able to decode the string. Try it using the following commands:
kubectl edit secret postgres-secret-config
returns
# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: v1
data:
POSTGRES_PASSWORD: UGFzc3dvcmQ=
kind: Secret
type: Opaque
metadata:
creationTimestamp: "2023-07-02T06:58:48Z"name: postgres-secret-config
namespace: default
...
Clearly this approach is unacceptable because not only is the password accessible within the cluster, but we cannot commit this to a public source control repository as any person with access to this repository will be able to read the password. Fortunately, this is not the end of the road. We can still salvage this situation by taking a step further by encrypting this Secret object by using a third party tool called SealedSecrets from Bitnami. Like many cases, you often have other choices. They are Vault from Hashicorp, and sops from Mozilla. To do this, we need to install its controller to our k8s cluster, and we need its accompanying cli called kubeseal.
Sealed Secrets
Install kubeseal to /usr/local/bin/kubeseal.
mkdir -p ~/Downloads/kubeseal
cd ~/Downloads/kubeseal
wget https://github.com/bitnami-labs/sealed-secrets/releases/download/v0.22.0/kubeseal-0.22.0-darwin-amd64.tar.gz
tar -xvzf kubeseal-0.22.0-darwin-amd64.tar.gz
sudo install -m 755 kubeseal /usr/local/bin/kubeseal
Install SealedSecret controller by applying this controller.yaml file.
Now we have everything we need (cli, controller, and Secret object) to create a SealedSecret object. We choose to install this SealedSecret controller to the default cluster controller which is kube-system. Format can be either json or yaml. We choose yaml to be consistent with other files.
Kubeseal uses a public key from this controller to encrypt the data. It can only be decrypted by the cluster because only this cluster has access to public key’s corresponding private key.
If you inspect this Secret, you will be able to see POSTGRES_PASSWORD’s base64 encoded value in plain sight. Anyone who can access your cluster with the right permission can still view the password with the following command.
kubectl edit secret postgres-secret-config
returns…
# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: v1
data:
POSTGRES_PASSWORD: UGFzc3dvcmQ=
kind: Secret
type: Opaque
metadata:
creationTimestamp: "2023-07-02T06:58:48Z"name: postgres-secret-config
namespace: default
...
… and we get its base64 encoded string. Are we back to square one? Let us say that the devops (you) is not the only person who can access this cluster. You might allow a developer to also access this cluster so that they can deploy their api. However, you may not want to expose the database password to them. If that is the case, you may choose an authorization system like RBAC to restrict access.
Remember that our api server itself will get access to the database password because otherwise, the api cannot talk and to it and store data! Since the Secret object cannot be accessed by developers, one thing they can try is to sneak in a code that reads the password to be sent elsewhere — if code review did not manage to flag that of course! If it is okay for the developer to know the production database password, none of this matters and SealedSecret is sufficient, and you can let the developer access the cluster normally.
In conclusion, you need to create a threat model assessment before deciding on what to do. There are a lot more details about this threat model process so whatever security decisions you want to make, it needs to be done properly.
Volumes
We need to create a storage space for the database to store data. We will create two objects which are PersistentVolume (PV), and PersistentVolumeClaim (PVC). PersistentVolume is how we create a ‘space’ for the data to live. PersistentVolumeClaim on the other hand is how we request a portion of space from that PersistentVolume. We will only create 5Gi which is more than enough for our purpose. hostPath uses /mnt/data directory in one of the nodes to emulate network-attached storage. This is a bad idea to use in production because if you lose this node, all data will be gone. For production setup, use a proper external storage like EBS or NFS. More details in kubernetes’ PV documentation.
Note the PersistentVolumeClaim name, ‘postgres-pv-claim’, is important for our next object which is Deployment to refer to.
Apply with
kubectl apply -f pv.yaml
kubectl get pv postgres-pv-volume
# returnsNAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
postgres-pv-volume 5Gi RWX Retain Available manual 5s
Notice that its status is set to available. We will see how that changes once our claim succeeds.
kubectl apply -f pvc.yaml
kubectl get pv postgres-pv-volume
# returnsNAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
postgres-pv-volume 5Gi RWX Retain Bound default/postgres-pv-claim manual 45s
You can see it is changed to ‘Bound’. The ‘Claim’ column now shows which PersistentVolumeClaim has claimed it.
HostPath
Another important thing you need to remember especially when we are using HostPath is postgres data will persist even when you delete your PersistentVolume. Verify with
The data is still here even when PersistentVolume was already deleted. Keep this in mind when updating your password in your Secret object, because the password needs to be updated within Postgres as well.
Deployment
The last two remaining objects are Deployment and Service. Deployment object runs our database as a Pod while Service exposes the application, so other apps in the cluster can communicate with it. A Pod is the smallest worker unit in your cluster. Inside, you can have one or more containers. If you have more than one, these containers are always together sharing resources and scheduled as a single unit. To scale your application up, you can increase the number of replicas in your Deployment and in turn the number of Pods will correlate with how many replicas you set.
Here we name our Deployment as ‘postgres’ with a single Pod enforced by replicas: 1; so only one Pod for this one Deployment. The container image is postgres:16.0. I like to explicitly state its major and minor version instead of using the latest tag because it will be easier to reproduce when you run into an issue.
For configuration values, we load them from environment variables in two ways. .spec.template.spec.containers[0].envFrom loads our ConfigMap object by name while .spec.template.spec.containers[0].env loads our database password from the Secret object.
The .spec.template.spec.containers[0].env.name has to match what postgres expects as an environment variable which is POSTGRES_PASSWORD. The .env.valueFrom.secretKeyRef.key, on the other hand, although it has the same string, has to match with what we have in sealed-secrets.yaml
# /k8s-devops/db/deployment.yaml
env:
...valueFrom:
secretKeyRef:
name: postgres-secret-config
key: POSTGRES_PASSWORD <- must match with
# /k8s-devops/db/sealed-secrets.yaml
spec:
encryptedData:
POSTGRES_PASSWORD: AgCAJxd4LMUD9O18E5yt... <- match with this
Next, the Postgres default volume mount which is /var/lib/postgresql/datawill use PersistentVolumeClaim that we already have created.
Apply with
kubectl apply -f deployment.yaml
Check that your database is up by using kubectl’s get subcommand followed by the object (Deployment) and its name (postgres).
kubectl get deployment postgres
# returnsNAME READY UP-TO-DATE AVAILABLE AGE
postgres 1/1 11 3m49s
If we check how many Pods we have, we only get one, as expected due to replicas: 1.
kubectl get po
# returnsNAME READY STATUS RESTARTS AGE
postgres-5598db5bb4-jznqd 1/1 Running 0 11m
Service
A Service object is how Pods and Deployments can be accessed. It creates a corresponding DNS entry for other applications to refer to. The DNS is created in a format of <service-name>.<namespace-name>.svc.cluster.local so that means our DNS entry will be postgres.default.svc.cluster.local.
The Service name can be arbitrary, but has been set as ‘postgres’ like the Deployment name, just to make it confusing.
There are four types of services which are NodePort, ClusterIP, LoadBalancer, and ExternalName. If not specified, it will default to ClusterIP. ClusterIP means this Service is mapped to an IP address across nodes, but only available within the cluster. NodePort makes it available to the outside by exposing a static port on each node, then forwards requests to ClusterIP. LoadBalancer type is used with external load balancer with an Ingress object, or managed k8s clusters such as Amazon’s or Google’s. ExternalName maps a Service to a DNS name.
Port is 5432 which is postgres’ default port number. Of course this setting can be changed using the ConfigMap technique we have seen.
Apply with
kubectl apply -f service.yaml
Check with
kubectl get svc
# returnsNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 10d
postgres ClusterIP 10.105.21.101 <none> 5432/TCP 3s
At this stage, the database can be accessed within the cluster. I think it is important to attempt this because it can dispel some of the magic k8s handling of networking so let us try and do that. The IP address 10.105.21.101 we see above is curious, so maybe we can do something with it.
Let us try doing a simple netcat to show that the database listens to the address and port we think it is. First, SSH into one of the worker Pods. If you followed my previous post, it is one of the three of 172.16.16.20{1,2,3}.
ssh kubeadmin@172.16.16.201
If we run a netcat program (nc) with verbose output flag
Only the last line is relevant, and it shows that port 5432 is indeed opened. If you SSH to other nodes, it will show the same. This is because we defined a Service with ClusterIP type — this single IP can be used to access our database. In reality however, our (micro)services are not going to reference this IP address because it can always change. Instead, we use its DNS entry which is postgres.default.svc.cluster.local. The short version, postgres, can be used as long as you are calling from the same default namespace.
~~
Using netcat is a success, but it only shows the port is opened. A stronger evidence to show this is working is to connect using a postgres client like psql. The deployed database does not include this tool, but we can run a one-off Pod that runs psql command and attempts to log in. We need to retrieve database the password and store it in a variable. The secret is encoded with base64, so we need to pipe it with a decoder.
Without -o jsonpath..., it will return a full JSON file. We can traverse the file using the k8s way with {.data.POSTGRES_PASSWORD}. It is almost similar to how jq does but there is a dot in front.
Next we run this Pod named with psql-client that deletes itself after it exits using --rm and --restart='Never'. It is critical that we set the password to PGPASSWORD environment variable along with other parameters. The user, database name, and port are what we expected. What is interesting is the host. We did not specify any namespace in the command below, so implicitly we are running under the default namespace. So to access the database, we simply use the name of the Service which is postgres. Accessing using this DNS name is the important part mentioned in the beginning of this post.
If you don't see a command prompt, try pressing enter.
my_db=#
From here, you can try out a command
my_db=# SELECT TRUE;
?column?
----------
t
(1 row)
Exiting (type \q) will delete the Pod
my_db=# \q
pod "psql-client" deleted
Should You Use A Database in Kubernetes?
The big question now is whether it is a good idea to use this database. For demonstration purposes, yes. But there are many considerations that we need to think about using a database inside a cluster. Data needs to persist as such that it should not be gone the next time we recreate our cluster. In the same vein, backing and restoring are an important aspect of database management. It also needs to be scalable, whether you are opting for highly-available (HA) or you want a separate write and read node. You also want a monitoring solution so you know if there are slow queries bringing down your applications. Many times it is easier to use a managed database solution rather than hosting on your own.
Things to consider when self-hosting a database
Can Backup AND Verify Restore
Includes stored procedures, triggers
A backup is useless if a restore has not been verified
Upgrade with zero downtime
Minor and major version
Security and TLS
Scale horizontally
Replicas
Read and Write Nodes
High Availability
Failover
Uptime - five nines
Monitoring
Cloning
Connection Pooling
Partitioning / Sharding
Nevertheless, deploying a proper database in k8s properly is certainly possible. There are several projects that have the above features integrated like CrunchyData Postgres Operator, Zalando, Cloud Native PG, and others.
We did not go full throttle with those solutions but deploying this way gives a lot of opportunities to learn various k8s objects particularly PersistentVolume, PersistentVolumeClaim, and Secret.
Backend
For our api backend, it is going to listen and process requests to and fro the frontend. So this part needs to be port forwarded. Within the cluster, the api needs to communicate with the database. From the previous section, we already know how. We are not going to use its IP address because that can change. Instead, we need to use its DNS entry which is postgres. Lastly, database migration needs to happen because there’s no table created yet.
Why Go
The backend is going to be a Go program just to simplify things. A Go program can compile to a self-contained single statically-linked binary. That means you can simply hand over this single binary path to systemd, or even type ./api and it will run without any external dependencies. Go’s built-in standard library is extensive and covers many use cases meaning for our simple api, we do not need many third-party libraries or use any frameworks to create a production-grade api server. In fact, this api only uses two external libraries — one for Postgres database driver, and another for database migration. All other things including router multiplexer (mux), cors middleware, reading config, graceful shutdown, and HTTP server are handled by the standard library. However, to be fair this api is a simple program without both authentication and authorization, no input validation, no caching, and no testing.
The api’s entry point is located at cmd/api/main.go. We create a new server that reads configuration from environment variables, sets up the router, and connects to the database. We have three routes; a /healthz to see if the api is up, a /ready endpoint to see if it has a database connection by running SELECT true;, and a /randoms endpoint that lists the latest ten UUIDs as well as to create a new one. We also have CORS middleware set up because the origin address and port from the frontend (:8080) is going to be different from this api (:3080).
The two endpoints, /healthz and /ready are typically found in an api program to be used with k8s. In a Pod lifecycle, a Pod is in a Running state when the Pod has been bound to the node, all containers have been created (we only have one), and at least one container is running. These endpoints are used by container probes as extra feedback to let k8s know if this Pod is ready to accept user requests. A particular Pod may not have a connection to the database, so we might prefer to route incoming requests to another Pod that is ready. K8s queries /ready endpoint (that does SELECT true;) to find out if it should route the requests or not. The /healthz endpoint on the other hand is used in conjunction with ’livenessProbe’. This probe is used to indicate if the container (our api) is running. In a situation where the api crashes, liveness probe will return a fail result, and it will kill the container. We designed our api in such a way that it can recover from a panic (it’s like an exception but in Go) so hopefully a crash will not happen. More details on the type of probes here.
Environment Variables
The app connects to the database using a connection pool. All of these settings are read from environment variables.
Moving on, the api listens for requests at the address host:port initiated by the function server.ListenAndServe() in a separate goroutine which is done by calling it inside an anonymous function prepended with go keyword.
// /k8s-api/cmd/api/main.go
...continue from main()
addr := fmt.Sprintf("%s:%d", srv.Api.Host, srv.Api.Port)
log.Printf("running api at %v\n", addr)
server :=&http.Server{Addr: addr, Handler: srv.Mux}
gofunc() {
if err := server.ListenAndServe(); !errors.Is(err, http.ErrServerClosed) {
log.Fatalf("ListenAndServe(): %v", err)
}
}()
Graceful Shutdown
Imagine our api is chugging along and handles traffic normally, and then we want to do an update to it. We create a new commit, push to a repository, image is now built and now k8s want to deploy this new version to the cluster. K8s creates new Pods with the new version in the cluster and now traffic goes to both Pods containing old and new versions of the api. Once all (or some, depending on deployment strategy) new Pods are up, old Pods will be shut down. Two questions need to be asked, what happens to requests that are still being processed in the api after k8s wants to shut the Pod down?; and would not the api needs to free (close) database connection so others can use it?
If the Pods are killed abruptly to make way for new Pods, requests that have not been completed will also be immediately terminated and users will get an error. This is definitely not a desirable behaviour, and we need to remedy this.
When k8s wants to shut a Pod down, it first sends an operating system signal called SIGTERM to the Pod and this marks the beginning of a default 30-second grace period. We need the api to capture this signal, so it knows not to accept any more requests and begin the process of shutting down which includes taking the chance to close all remaining resources like closing database connection, other HTTP calls, opened files, or other resources.
To implement graceful shutdown, we create a buffered channel to catch all terminate (SIGTERM), stop (SIGSTOP), and interrupt (SIGINT) operating system signal to a variable called stop. Once the channel receives any of these signals, it does two things. Firstly, the api’s HTTP server stops receiving any more new requests and secondly, the line <-stop unblocks and runs subsequent lines. First thing it does is it runs server.Shutdown() line with a timeout we define as five seconds. If everything goes well, the next piece of code which is database shutdown is run and finally api exits and the Pod is removed.
However, if k8s gets no response after the default of a 30-second grace period, k8s is going to do a hard kill using SIGKILL. This signal cannot be caught by the api process so any remaining resources cannot be closed gracefully. This is why it is important to do the graceful shutdown in the api ourselves.
If we zoom out and look at how k8s handles termination lifecycle, k8s will immediately set the Pod’s state as ‘Terminating’ and stops sending any more traffic to it. This is great which means k8s already does one job for us. Shutting down resources are still necessary though.
Note: In other applications where nginx is being used in front of an api, nginx will intercept that signal and will perform a graceful shutdown. However, the api still needs to close all other resources like database, network connections and others.
Note: Requests that take longer than the grace period will be cancelled and cause bad user experience. You can extend this grace period, but you have to evaluate if doing so is the correct approach.
Trivia: Ever had to use Ctrl+C to stop things in the terminal? you are actually sending a SIGINT signal! Ctrl+Z is SIGSTOP.
Migration
For database migration, we are supporting both one-level ‘up’ and ‘down’ operations. Which operation to run is determined by a flag that accepts either ‘up’ or ‘down’. We will see that through kubernetes, we can pass command line flags to determine the direction of migration.
All in all, we have built a simple production-grade api server that can list and create records, runs migration, and has graceful shutdown using only Go’s excellent standard library plus two external dependencies, and without any HTTP server like nginx in front of it.
Tagging
After talking in great length about the api design, we can move on to building container images. We will be making a new image for every git commit so that we can differentiate one image from another. One easy way is to use tags, which are simply strings that we can use to identify a particular commit or build. We need this to be unique-ish so there are no name conflicts when choosing which image k8s is going to pull. There are three (but not limited to) possible ways to construct this string. Firstly, we can tag the image the same as our api’s version, for example if our api version is v1.2.3, we also tag our image the same. Secondly, we can simply use our api’s latest git commit. Thirdly, a combination of the first two. Here, I am showing the second approach.
TAG=$(git rev-parse HEAD)echo$TAG
This will yield its SHA hash that looks like this: 334ed70d2fcbdb6936eaef84b7385fab8b545b0a. Some people like a shorter version which can be done by adding --short parameter.
The short version can look nicer when combined with api’s version for example gmhafiz/api:v1.2.3-334ed70.
Once the image is tagged, we can easily reference that from our kubernetes Deployment object. But before going into that, let us take a step back and build an image.
Containerise
What is left we need to turn this codebase into an image. We use a multi-stage technique for this so the final image only contains necessary files and thus keeping it small. In the first stage we name as build, we copy dependency files go.{mod,sum} and run go mod download to retrieve third-party dependencies. For subsequent builds, if there are no modification to the both dependency files, no download is necessary because it will simply use Docker cache making image building much faster.
# /k8s-api/Dockerfile-apiFROM golang:1.21 AS buildWORKDIR /go/src/app/# Copy dependencies first to take advantage of Docker cachingCOPY go.mod ./
COPY go.sum ./
RUN go mod download
To compile, copy all the files and run go build command. The ldflags -w and -s strips debugging symbols because those are not needed for production. We name the final binary as api using the -o flag.
# /k8s-api/Dockerfile-apiCOPY . .
# Build Go BinaryRUNCGO_ENABLED=0GOOS=linux go build -ldflags="-w -s" -o ./api cmd/api/main.go
That completes the first stage. In the second stage, we pick a minimal base image called distroless. We could have used scratch image that contains nothing because our Go binary is self-contained. However, a distroless image has the added convenience of included ca-certificate for external TLS URL call and timezone built into the image. Also, we use nonroot tag so our api runs in a rootless container. We then copy the binary from the previous stage to /usr/local/bin/api and set its entrypoint.
To build this image, we supply the path to this file using the -f flag. This was only necessary because we picked a file name other than Dockerfile. We name this image as gmhafiz/api. The name must match with the repository path we will see later. For now, we simply use the format of <docker login name>:<repository name>. We also tag this image with its git SHA hash. Without it, it will default to latest. The dot in the end simply means current directory.
The resulting image only contains our single compiled binary along with what distroless image provided — thanks to the multi-stage approach. In the final image, there are no compile tools, operating system, shell or other stuff not needed to run this api resulting in a relatively small image size at around 11 megabytes.
One other thing we need to do is to create the database table and subsequently populate some random UUIDs. Its Dockerfile is identical to the api’s except it has a different binary name, and thus a different entrypoint.
# # /k8s-api/Dockerfile-migrateFROM golang:1.21 AS buildWORKDIR /go/src/app/COPY go.mod ./
COPY go.sum ./
RUN go mod download
COPY . .
RUNCGO_ENABLED=0GOOS=linux go build -ldflags="-w -s" -o ./api cmd/migrate/main.go
FROM gcr.io/distroless/static-debian12:nonrootLABEL com.example.maintainers="User <author@example.com>"COPY --from=build /go/src/app/migrate /usr/local/bin/migrate
ENTRYPOINT ["/usr/local/bin/migrate"]
To build, pick a different name, like gmhafiz/migrate
For our cluster to retrieve this image, it needs to be stored somewhere. We can buy a domain name and reverse proxy to a container registry hosted in our server we own, or use ngrok if you do not want to buy a domain name yet. For now, the easiest way is to simply use a free solution like Docker hub registry. This registry is a special repository of images that k8s can pull images from. There are many other hosted registries like Github, Gitlab, from the big three cloud services, self-hosted from quay.io, docker registry, Harbor, peer-to-peer ones like Uber’s kraken, and many others.
First create a new repository from the web at https://hub.docker.com/repository/create. Note that the namespace and repository name is reflective of our image’s name of gmhafiz/api.
Once the repository is created, you may push it.
docker push gmhafiz/api:${TAG}
When you refresh, you will see the image has been successfully uploaded and is ready to be downloaded by your cluster.
Secrets
There is a reason why there are separate demo repositories you see at the top of this post. In this fictional case, the fullstack developer only develops the frontend and backend but fortunately has no access to the production database. Cluster management including managing database password is left to us, the devops. If you see in the applications/api directory, there is no Secret object, instead the api will reference the same Secret object as the database.
The api requires credentials to the database for it to work. However, the backend developer is not privileged to this information as they are sensitive. Only devops or database architect teams are privy to this information. The database sealed-secrets.yaml file is encrypted so the password cannot be retrieved by the api developer even when the files are hosted in a public repository. A potential issue is when api developers are also allowed access to the k8s cluster. There can be many reasons for this. We might allow api developers to see if their api is deployed. We might also allow them to scale up or down its Pods. However, giving users full access to the cluster by sharing the same credentials as cluster admin also means that the api developer can retrieve database password which we do not want. To prevent this, we need to apply an authorization system. Fortunately, Kubernetes has one built-in. Let us make a new user in the cluster with restricted access using Role-based Access Control.
Note: Username and password is not the only way for the app to access the database. We want the connection to be encrypted such as using TLS. That means creating a signed client certificate for the app. However, we still need to define variables like database port and host name.
RBAC
In a Role-based Access Control (RBAC), we apply a rule saying an entity(dev007) has a role(dev) to perform(deploy) a deployment. All this can be done with a k8s object called Role and RoleBinding. They way we design is following k8s’ default behaviour which is Principle of Least Privilege, which means by default, we deny everything, but we are going to add or allow specific rules (whitelist).
Create User
First step is to create a user. There is a great guide at https://docs.bitnami.com/tutorials/configure-rbac-in-your-kubernetes-cluster/ that creates a separate namespace that I refer to a lot, so I will breeze through here. What I am showing differs in such a way that this dev007 is going to be in the same ‘default’ namespace instead.
To create a user, we make use of Public Key Infrastructure (PKI). There are alternatives to PKI approach like external auth such as OPA Gatekeeper, Kyverno, OAuth, etc. The downside of PKI is we cannot revoke a user’s certificate without also revoking all other users’ access in the cluster.
The user dev007 needs to run a series of commands:
### Run by user 👷 dev007 only.# Create a private keyopenssl genrsa -out dev007.key 2048# Very private, don't expose to anyone else except user dev007chmod 400 dev007.key # ensure only dev007 has the permission to read this file.# User dev007 creates a certificate signing request (CSR). The CN (Common Name) is the # important identity name.openssl req \
-new \
-key dev007.key \
-out dev007.csr \
-subj "/CN=dev007"
The .csr is sent to the cluster admin which is us to be signed and to create an X509 client certificate.
### Run by 🦸🏽♂️ cluster admin# Locate your cluster's CA (certificate authority) to sign this CSR.# Location is in /etc/kubernetes/pki/ so you may need to SSH into one of the nodes.# dev007 sends the csr file to cluster admin. And cluster admin signs it and returns dev007.crt# file to that user.openssl x509 \
-req \
-in \
dev007.csr \
-CA CA_LOCATION/ca.crt \
-CAkey CA_LOCATION/ca.key \
-CAcreateserial \
-out dev007.crt \
-days 7# Best practice is to make it short, and renew.
We can inspect the content of the certificate with the following command and see the window period of validity.
openssl x509 -in dev007.crt -text -noout
# returnsCertificate:
Data:
Version: 1(0x0) Serial Number:
12:b5:db:df:38:6d:04:22:99:56:0b:ec:f4:54:c6:2d:a3:02:34:24
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN= kubernetes
Validity
Not Before: Jul 16 04:09:46 2023 GMT
Not After : Jul 23 04:09:46 2023 GMT
Subject: CN= dev007
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
RSA Public-Key: (2048 bit) ...
Logging In (Authentication)
dev007 is able to log in using the two files, this client certificate (dev007.crt) generated by k8s admin, and private key (dev007.key) generated by that user earlier. The first step is to create a new credential (new user) using set-credentials command:
### Run by user 👷 dev007.kubectl config set-credentials dev007 \
--client-certificate=/home/dev007/.certs/dev007.crt \
--client-key=/home/dev007/.certs/dev007.key
Cluster name is kubernetes if you follow my previous guide of vanilla installation. If using minikube, the cluster name is minikube. Find out the name by looking at your ~/.kube/config file.
The user dev007 can set the context called ‘dev-context’ with the following:
### Run by user 👷 dev007.kubectl config set-context dev-context --cluster=kubernetes --user=dev007
At this time, the user dev007 will not be able to access anything yet.
### Run by user 👷 dev007.kubectl --context=dev-context get pods
# returnsError from server (Forbidden): pods is forbidden: User "dev007" cannot list resource "pods" in API group "" in the namespace "default"
Because that is the default behaviour which is to deny all. You need to whitelist what the role that user dev007 belongs to is allowed to do.
Create RBAC Policy
We need two more objects, a Role and a RoleBinding. This Role named ‘dev’ is in the current default namespace because we did not specify one here. Under an array of rules, the first item is apiGroups. Empty string "" indicates this is the core API group.
# /k8s-devops/role.yamlkind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: dev
rules:
- apiGroups: ["", "apps"]
# we allow developers to see deployment, pods, and scale up or down resources: ["deployments", "replicasets", "pods"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
We also add apps to this apiGroup. ‘apiGroups’ documentation is probably hidden from the official docs because I cannot find it using the search box, but we can list what ‘apps’ is for with the following command. We can see that ‘ReplicaSet’ is among them.
If you notice, I tend to use the short form to save up typing. For example po for pods. deploy for deployment and so on. The kubectl api-resources lists these short forms to save some typing.
We want to allow dev007 to deploy, scale and see pod logs, so we add to the ‘resources’ list. Finally, we whitelist what this role (verbs) can do. Notice that there is no Secret object in the resource list. This prevents anyone with the role ‘dev’ from inspecting any Secret content.
To apply dev007 user to this role, we use a RoleBinding object. Since we only have one user so far, there is only one item is in the .subjects array.
# /k8s-devops/role-binding.yamlkind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: dev-role-binding
subjects:
- kind: User
name: dev007
apiGroup: ""roleRef:
kind: Role
name: dev # must match with Role's metadata.nameapiGroup: ""
As the cluster admin, apply both with
kubectl apply -f role.yaml
kubectl apply -f role-binding.yaml
# returnsrole.rbac.authorization.k8s.io/dev created
rolebinding.rbac.authorization.k8s.io/dev-role-binding created
If user dev007 retries the get pods command,
kubectl --context=dev-context get pods
# returnsNAME READY STATUS RESTARTS AGE
postgres-5598db5bb4-jznqd 1/1 Running 1(88m ago) 7d1h
It returns one database Pod as expected because this database has already been deployed. Now, let us try to access the Secret object.
kubectl --context=dev-context get secret
Error from server (Forbidden): secrets is forbidden: User "dev007" cannot list resource "secrets" in API group "" in the namespace "default"
As expected, the user cannot access the Secret object because the role ‘dev’ does not have access to it.
This concludes the Secrets section and in summary, this is what we have in this section:
User name : dev007
context : dev-context
role : dev
role-binding : dev-role-binding
API Settings
That was a long detour from Secrets section. But jumping back to api, from its point of view, it needs to have the environment variable for database password, api’s host, and api’s port. We already have created a SealedSecret for database password, so we can reuse that. For the rest of those api settings, we can create a new ConfigMap. Remember that the api developer has no idea what these values are. Only the k8s devops person knows and manages these values.
API_PORT environment variable is going to be an integer 3080. The database port on the other hand is going to be the integer 5432. The rest are the database’s user, name and host. Notice that the DB_HOST value is ‘postgres’ which is the DNS entry for postgres service.
# As devops# /k8s-devops/db/configmap.yamlapiVersion: v1
kind: ConfigMap
metadata:
name: api-parameters
labels:
app: api
data:
# to read a value as integer, use its hex value from ascii commandAPI_PORT: "\x33\x30\x38\x30"DB_USER: "user"DB_NAME: "my_db"DB_PORT: "\x35\x34\x33\x32"DB_HOST: "postgres"
In both API_PORT and DB_PORT, you can see some strange encoding. ConfigMap can only store string. It even cannot store an integer or boolean either. Our api however cannot accept a string as integer because Go is a statically typed language. We can modify our api to read the ports as strings, then convert to integers. We can consider putting DB_PORT into our Secret. The same goes with API_PORT, although it is not really a secret. Other ways include using a Helm chart, and injecting environment variables. ConfigMap allows us to embed a file so perhaps our api can parse a yaml file instead of reading configurations from environment variables.
All those options are a headache so one trick we can use here is to use values seen from the ascii with hex table flag switched on.
As you can see from the fourth column, the encoding for 0 or zero, is hex 30. For the number 5, go down the column, and you will see it is 35. To construct a series of integers, what we need to do is to escape the literal encoding for hex using \x and pick the numbers.
Decimal
Result
5
\x35
4
\x34
3
\x33
2
\x32
Thus, the integer 5432 then becomes \x35\x34\x33\x32.
Apply with
kubectl apply -f configmap.yaml
At this stage, you should have three ConfigMaps in the cluster.
kubectl get cm
# returnsNAME DATA AGE
api-parameters 5 18s
db-credentials 2 25m
kube-root-ca.crt 1 7d11h
Deployment
Now that we have both ConfigMap and Secret applied, we can create a Deployment. We give it a name as server with three replicas, so there are going to be three Pods.
The .spec.strategy specifies how we replace old Pods with new ones. We did not specify one when deploying our database, so it defaults to rollingUpdate. Other strategies are recreate, blue-green, canary, and more advanced way with A/B deployments. In rollingUpdate, since we have three Pods, upon a new deploy, k8s will spin up one Pod and wait for it to be ready before replacing the next Pod. This is because maximum surge is 25%. In other words, it will only replace a rolling 25% of the Pods at a time. This also means while deployment is underway, requests will to go to either old or new pods.
Then we specify an array of containers. We only have one called ‘gmhafiz/api’. The image is also tagged to our latest git commit hash. If we want to update our deployment, this is where we edit in order to push the latest code to production!
Resources are important. Here we limit memory consumption to 128Mi and cpu cycles are limited to 500m.
Then we tell k8s that in order to check if the api is ready to receive requests, query /ready endpoint at port 3080. This is done by the .spec.containers[].readinessProbe setting.
The last two remaining parts are configuration files. Database password is loaded from ‘postgres-secret-config’ secret while all other api configurations are loaded from ‘api-parameters’ ConfigMap.
Although the key to the password is POSTGRES_PASSWORD (which is what postgres expects), we can redefine it to what our api expects to be DB_PASS.
Apply with
kubectl apply -f server.yaml
and check with kubectl get deploy and you will see three replicas are ready and available:
kubectl get deploy
# returnsNAME READY UP-TO-DATE AVAILABLE AGE
postgres 1/1 11 5d23h
server 3/3 33 6d15h
Migrate Up
Our api is now deployed and can connect to the database. However, the database has no table yet. We can SSH into the cluster and use the one-off Pod trick to connect to the database we saw in the database section and manually copy and paste our migration sql file. But this approach is imperative and you need to remember many commands with manual copying and pasting.
A more elegant solution is to run a one-off Job that runs the migrate command. So let us prepare its container image first.
# k8s-api/Dockerfile-migrateFROM golang:1.21 AS buildWORKDIR /go/src/app/COPY go.mod ./
COPY go.sum ./
RUN go mod download
COPY . .
RUNCGO_ENABLED=0GOOS=linux go build -ldflags="-w -s" -o ./migrate cmd/migrate/main.go
FROM gcr.io/distroless/static-debian12:nonrootLABEL com.example.maintainers="User <author@example.com>"COPY --from=build /go/src/app/migrate /usr/local/bin/migrate
ENTRYPOINT ["/usr/local/bin/migrate"]
As you can see, our migration image is very similar to api’s. We use ENTRYPOINT at the end that runs the migrate binary. If only that command is supplied, it will do a default ‘up’ migration. If we supply a flag using -go, we can choose to migrate the other direction which is ‘down’.
Since both api and migrate binaries share the same tag, this may be an undesirable side effect. Api tends to be updated more often which means its tag will also change often. The migrate image however has to follow suit even though there might be no change at all.
As you can see from the code below, it also needs database credentials which are read from the environment variable. So in the Job manifest below under the ‘migrate’ container section, we put in the same ’envFrom’ and ’env’ to pull the values from Secret and ConfigMap respectively. As an api developer, they do not have to know the database password. Only you as a devops can.
Another critical part in this Job is restartPolicy needed to be ‘Never’. The only other option is ‘OnFailure’ because the ‘Always’ option does not exist for this Job object. Upon a failure, we always want to inspect the logs rather than having k8s to retry again and again.
kubectl apply -f migrate-job.yaml
K8s will run this job as a Pod. That means we can try and look for its logs.
kubectl get pods
#returnsNAME READY STATUS RESTARTS AGE
migrate-8rpjn 0/1 Completed 0 38s
The migration should be quick because not a lot of data was inserted. Notice that although the run has been completed, it is not removed from the cluster. This allows us to view the logs. To see the logs, we pass in the Pod’s name, along with a flag to follow.
# Run as developerkubectl --context=dev-context logs -flu migrate-8rpjn
# returnsError from server (Forbidden): pods "migrate-8rpjn" is forbidden: User "dev007" cannot get resource "pods/log" in API group "" in the namespace "default"
As the devops, role.yaml needs to be modified to allow developer access.
# k8s-devops/role.yamlkind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: dev
rules:
- apiGroups: ["", "apps"]
resources: ["deployments", "replicasets", "pods"] # we allow developers to see deployment, pods, and scale up or downverbs: ["get", "list", "watch", "create", "update", "patch", "delete"] # You can also use ["*"] - apiGroups: ["", "batch"] # <-- add new ruleresources: ["jobs", "pods/log" ]
verbs: ["get", "list", "create", "delete"]
A second rule is added for ‘batch’ apiGroups. This allows the developer to run (and delete) this job. Under resources, ‘pods/log’ is added which allows logs to be viewed by developers.
Once we are done viewing the logs, we can delete this Job. If you do not care about the logs, it can be deleted automatically using .spec.ttlSecondsAfterFinished documented at https://kubernetes.io/docs/concepts/workloads/controllers/job/#clean-up-finished-jobs-automatically. However, it is a good idea to collect these logs to a centralised log system like Loki, ElasticSearch or Splunk. Otherwise, it will be gone forever.
# Run as 👷 developerkubectl --context=dev-context delete jobs/migrate
# returnsjob.batch "migrate" deleted
Migrate Down
Because we useENTRYPOINT in our yaml manifest file, we can overwrite what commands and flags we want to pass to this program. To do that we need to supply a combination of both command and args. command has not changed, but we can supply an array of arguments. The one we desire is migrate -go down so we give each cli argument as an item in the args array.
Then simply re-apply this yaml file to migrate down one level. The same Job cannot be run twice. So if you have not deleted the ‘migrate up’ Job we ran before, it it needs to be deleted first.
kubectl delete job migrate-job # if you have not run thiskubectl apply -f migrate-job.yaml
If you the above commands, do not forget to re-run the migrate up again lest you do not have a table in the database!
Service
The final thing to make api accessible by creating a Service object for this api. It is similar to database’s Service where we restrict it to TCP.
# /k8s-devops/api/service.yamlapiVersion: v1
kind: Service
metadata:
labels:
app: server
name: server
spec:
type: ClusterIP
ports:
- port: 3080protocol: TCP
targetPort: 3080selector:
app: server
Apply with
kubectl apply -f service.yaml
Confirm ‘server’ Service has been created and exposed at port 3080 with
kubectl get svc
#returnsNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 17d
postgres ClusterIP 10.105.21.101 <none> 5432/TCP 7d2h
server ClusterIP 10.101.141.71 <none> 3080/TCP 139m
Access
Just like a database, let us try to SSH into one of the nodes and try hitting the /ready endpoint to confirm that the api can talk to the database.
ssh kubeadmin@172.16.16.201 # ip address of your node, and it depends on your setup
Then using the ClusterIP address we saw above,
curl -v 10.101.141.71:3080/ready
# returns* Trying 10.101.141.71:3080...
* Connected to 10.101.141.71 (10.101.141.71) port 3080(#0)> GET /ready HTTP/1.1
> Host: 10.101.141.71:3080
> User-Agent: curl/7.88.1
> Accept: */*
>
< HTTP/1.1 200 OK
< Access-Control-Allow-Headers: Accept, Content-Type, Content-Length, Authorization
< Access-Control-Allow-Methods: POST, GET, OPTIONS, PUT, DELETE
< Access-Control-Allow-Origin: *
< Date: Sun, 09 Jul 2023 10:26:57 GMT
< Content-Length: 0<
* Connection #0 to host 10.101.141.71 left intact
It returns a 200 OK response which means the api can talk to the database! Notice that we use an IP address once we SSH into one of the nodes. The Pods themselves have an entry in their /etc/resolv.conf file to help the correct IP address when referencing using postgres host.
Inspect DNS
Unfortunately we cannot inspect the content of this /etc/resolv.conf file because our container’s base image is bare minimum — there’s no shell, cat, tail, nano, etc. What we can do is to use another base image that contain the necessary tools for debugging. Rebuild a new image using a ’normal’ base such as debian:12 instead of distroless.
Use debian:12 image and install curl (optionally netcat too)
As you can see, the content of /etc/resolv.conf are different from the nodes’ and the Pod’s. Pod’s DNS entry is managed by k8s while nodes’ are left untouched. Not so magical after all once you figure out what k8s did behind the scene.
Frontend
To visualise and interact with the api, we will build a simple single-page application (SPA). Frontend is not the main focus in this post, so I will only share important snippets only. Full code is in https://github.com/gmhafiz/k8s-web.
We need a view to show our list of ten UUID, so we create a new Vue component under the Views directory. In it, we need a method that calls the api and stores the result in data(). The URL needs to be the same as the one we will port-forward the api. To automatically call this get() method, we call it when the page gets mounted.
To display, we simply loop over randoms variable. Because this is Typescript, we declare that it is going to be a Random data structure where each item has an ID and a name. We can display them using the dot notation.
We also want a button that calls the api to add a new UUID just to show that connections can also go in. So we create a button so that on a click (@click), it calls the add() method with POST verb. On success, it will re-retrieve the latest ten UUIDs. Vue will take care of updating the UI, and it will show the latest data automatically. That’s right, all DOM manipulations are done magically. Of course, you can also make the POST request to return only the single created data and then append its result to the randoms variable instead of re-querying the list again.
Finally, we need to containerise this. Unlike our api program, this web UI needs a server that can serve this page because a folder on its own cannot serve itself. Something like nginx or caddy suffice. We continue to use multi-stage strategy like we have seen with api container build. Starting from the node image of version 18 (LTS version), we copy both package.json and its lock file (package-lock.json) and run npm install. In the second stage, we run nginx to serve static files from /usr/share/nginx/html. It is exposed at port 8080 which is the default port for this chainguard nginx image.
# k8s-web/DockerfileFROM node:18 as build-stageWORKDIR /appCOPY package*.json ./
RUN npm install
COPY . .
RUN npm run build
FROM cgr.dev/chainguard/nginx:1.25.1 as production-stageCOPY --from=build-stage /app/dist /usr/share/nginx/html
EXPOSE 8080
To build, run the following command. Just replace gmhafiz/web with your own repository name if you are following along.
Now as the devops, we only need to create two objects; a Deployment and a Service. Here we combine both Deployment and Service object in a single yaml file because these objects are logically grouped together (using --- as separator) and is recommended as a best practice. You can keep all db.yaml, api.yaml, and web.yaml in a single folder without worrying about file naming clashes, and finding them becomes a lot easier.
# k8s-devops/web/web.yamlapiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 1selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: gmhafiz/web:e2adcb710ce2feb645b2a5c3799d67e6d9554631
name: web
resources:
limits:
cpu: "500m"memory: "128Mi"
Two important bits are as follows. The first id .spec.template.metadata.labels.app which we labelled as web This is the label that our Service is going to refer to. Finally, we have a single container with the tagged image name.
To expose this Deployment, we need a Service object. The image exposes the web application at port 80 denoted by .spec.ports[0].port. We use targetPort for us to find this Deployment which happens to be the same number. .spec.selector.app is important because that is how this Service is going to find our Deployment above.
# k8s-devops/web/web.yaml---
apiVersion: v1
kind: Service
metadata:
labels:
app: web
name: web
spec:
type: ClusterIP
ports:
- port: 80protocol: TCP
targetPort: 80selector:
app: web
Apply with
kubectl apply -f web.yaml
Port Forward
This brings us to the last piece of this post which is port-forwarding. This technique forwards requests we make from the local computer into the k8s cluster. We only need to port-forward both api and the web. It is not necessary to port-forward the database because we do not interact directly with it. While this port-forward technique is sufficient right now, in a real-world application, you would want an Ingress instead.
To port-forward the api, we use port-forward sub-command followed by Service name. The last part of port number mapping is a bit unintuitive - it follows a <local>:<k8s> format meaning we want to map port 8080 exposed from k8s web Service to port 8080 in our local computer.
At this stage you should have two Services running in the cluster, one each for api and server.
kubectl get svc
#returnsNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 18d
postgres ClusterIP 10.105.21.101 <none> 5432/TCP 8d
server ClusterIP 10.101.141.71 <none> 3080/TCP 30h
web ClusterIP 10.109.238.205 <none> 8080/TCP 50s
To port forward run each of the following command in its own terminal
kubectl port-forward svc/web 8080:8080
# returnsForwarding from 127.0.0.1:8080 -> 8080Forwarding from [::1]:8080 -> 8080
kubectl port-forward svc/server 3080:3080
# returnsForwarding from 127.0.0.1:3080 -> 3080Forwarding from [::1]:3080 -> 3080
Now open your browser at http://localhost:8080, and you will see a Vue single-page application with ten UUIDs on the right!
If you look over the network tab, you can see this SPA sends a request to localhost port 3080. This request is then forwarded into the k8s cluster.
To reiterate that the api can communicate with database, let us add a new UUID by clicking the Add button:
A POST request was made and it re-retrieves the latest ten UUIDs which includes a new 101-th UUID.
CORS
Before we finish, let us make an adjustment to the api, so it only accepts api requests from http://localhost:8080 In the k8s-api repository, open cmd/api/main.go and restrict allowed incoming requests from everything using asterisk (*) to http://localhost:8080.
Whenever there is a mismatch between originating URL and api server, the browser will attach additional headers and sends an OPTION HTTP request, and if successful, it will continue with the intended API call. Our server already returns those three headers anyway to help browser to decide whether to continue doing the API call or not.
Commit and build a new image. Then push to container registry. There will be a new $TAG so this value needs to be applied to container image and yaml file.
In the devops repository, edit server’s image tag, so it will deploy our new image
vim k8s-devops/api/server.yaml
spec:
containers:
- image: gmhafiz/api:7f7bec15ce619a43a2ecb75dc3d56673322174f5 # <-- different tag
Simply apply this file and k8s will do its magic of rolling out new Deployment in the k8s cluster.
kubectl apply -f server.yaml
Once that is done, you will see everything still work the same.
To confirm that CORS is working, let us change the port our local port forward is listening to something other than 8080. Press Ctrl+C to terminate web’s port forward and pick another port, for example 8081.
kubectl port-forward svc/web 8080:8080
Forwarding from 127.0.0.1:8080 -> 8080Forwarding from [::1]:8080 -> 8080Handling connection for8080Handling connection for8080^C
kubectl port-forward svc/web 8081:8080
Forwarding from 127.0.0.1:8081 -> 8080Forwarding from [::1]:8081 -> 8080
Instead of http://localhost:8080, open http://localhost:8081 and you will see no api requests are working anymore! Open network tab and you will see a CORS error.
Further investigation shows that the browser sends ‘Origin: http://localhost:8081’ which is not in the allowed origin set in CORS settings in our api.
Calling the api using curl will continue to work. CORS only applies between browsers and servers because your browser first sends an OPTION HTTP request before doing a GET HTTP verb.
Conclusion
You have learned how to create three applications, database, api server, and a web single-page application and containerise and push each of them to a container registry. Database was deployed with extra authorizations steps. The API server was deployed in a more cloud-native way by following many of 12-factor app principles. Then, using k8s yaml manifest files, we deploy each of them into the cluster and expose them as service. Finally, port-forwarding allows us to access both api and web applications.
As you can see, a handful of yaml files were enough to deploy all three applications. Yaml files can be logically combined which makes it only three yaml files to manage. SealedSecret object needed an extra step to create though.
What is next? In real-life production settings, it is a very good idea to use a managed database solution instead of having the database in the cluster like this. There’s no TLS anywhere in between the applications so it is not secure thus that needs to be remediated. Finally, the applications we have here cannot be accessed from the Internet yet. That is what the next part is for which is Ingress which I hope will be the shortest of this three-part blog series ;)
Comparison between popular go libraries and ORM for database access layer.
We look over how normal and abnormal usage of these libraries and ORM helps protect (or not!) against
SQL injection. Remember that we accept various query parameters when listing a resource, ‘users`
records in particular. The result is limited to a maximum of 30 records. We are going to try to list
all records in one resource by formulating sneaking a malicious query parameter in the request.
http GET http://localhost:3080/api/sqlx/user?favourite_colour=blue;select%20*%20FROM%20users;,--;
We know that favourite_colour is a valid and accepted query parameter. We are going to see if
appending the url starting with an apostrophe, then a semicolon ;, followed by a select all
(select * FROM users), closing off with another semicolon, and an sql comment (--) will work.
apostrophe: Common way of closing off a string concatenation
semicolon: SQL way of closing of the previous sql statement
select%20*%20FROM%20users; select everything in users table. %20 is a space
double dash: SQL way of commenting out the rest of SQL queries.
This malicious URL is not the only way of trying to inject SQL queries. Others include using
AND 1=1 which means the query is always true, and the dreaded ';DROP DATABASE users-- which
mean adding a second SQL query to drop users table. You can try out with different urls by running
the examples in the provided example/rest.http file.
The post is incomplete without the addition of this comic:
There are two things we want to see how these libraries and ORMs behave. The first being if
malicious sql gets injected, and second how do they behave and the output that gets returned.
Testing against sqlx is the most interesting amongst all libraries and ORMs because we have made some
dodgy examples with string concatenations.
At the point of QueryxContext(), the fullQuery is correctly formed but the arguments get mangled
with the attempted sql injection.
fullQuery:
SELECT*FROM users WHERE favourite_colour = $1ORDERby id LIMIT30OFFSET0
arguments[0]:
blue;select * from users;,--;
It gives of an error saying invalid input value for enum valid_colours: "blue;select * from users;,--;"
This error comes from the pgx sql driver that we used.
Stepping back at the handler layer in db/filters.go file, the url.Values.Get("favourite_colour")
that we used when parsing query parameter simply return user’s input which why the first argument
also contains that string.
Fortunately sqlx returns an error although for a different reason,
invalid input value for enum valid_colours: "blue';select * from users;,--;"
Note that we can make a prepared statement like below but, it does nothing to prevent this type
of sql injection because the malicious part is in the argument, instead of this sql query.
stmt, err := r.db.PrepareContext(ctx, fullQuery)
if err !=nil {
returnnil, err
}
// no error
sqlc
Curiously, sqlc returns neither a result nor an error at all. The first_name filter is set to be
Bruce';select * FROM users;,--; and sqlc returns no result and no error at all. We get an empty
array as a response.
http GET http://localhost:3080/api/sqlc/user?first_name=Bruce;select%20*%20FROM%20users;,--;
squirrel
GET http://localhost:3080/api/squirrel/user?favourite_colour=blue';select%20*%20FROM%20users;,--;
Just like sqlx, it returns an error saying invalid input. It simply does not accept such parameter
and returns both an error and empty array result.
invalid input value for enum valid_colours: "blue';select * FROM users;,--;"
gorm
Like sqlx and squirrel, gorm also returns the same error coming from pgx sql driver.
invalid input value for enum valid_colours: "blue;select * FROM users;,--;"
models: failed to assign all query results to User slice
It appears that the query did run, but failed when scanning the results to a struct. To find out
what query that has been generated, we switch on the debug mode with boil.DebugMode = true
SELECT * FROM "users" WHERE ("users"."favourite_colour" = $1) ORDER BY id;
[{blue;select * from users;,--; true}]
But this is not clear if the argument is executed in the database. The next thing we can do is to
enable logging for our database, and we can check out its standard output result.
-- enable logging for database db_test
ALTERDATABASE db_test SET log_statement ='all';
Watch the logs at standard output with docker logs -f db_container and re-run the HTTP request.
2022-09-14 12:08:33.858 UTC [173403] ERROR: invalid input value for enum valid_colours: "blue;select * from users;,--;"
2022-09-14 12:08:33.858 UTC [173403] STATEMENT: SELECT * FROM "users" WHERE ("users"."favourite_colour" = $1) ORDER BY id;
It appears that the select * from users; statement did not run in the database.
ent
Ent on the other hand silently return an empty array because it cannot find any match for the value
blue;select * FROM users;,--; from our favourite_colour column.
Sql injection vulnerability in a codebase should not happen anymore. There are many well known best
practices to prevent this security vulnerability, among others is to always sanitise user’s input in
the handler layer, where user’s input are validated. And secondly, to parameterize sql arguments
instead of joining the strings manually by using placeholders, either with question marks (?) for
mysql or dollar signs ($) for postgres.
Among all these behaviors, none executed the malicious injected sql query. In terms of error
handling, I would prefer to receive an error when we receive invalid or malicious
http request. The reason being that we can log the request in the error handler. So the worst are
sqlc and ent where they do not return any error, but sqlx being the worse between the two because
it returns the first 10 records nevertheless.
Conclusion
What initially started to have eight posts has become twelve over the course of a year. But I hope
I have covered common use cases when interacting with a database.
We have seen how easy an ORM especially ent and gorm when it comes to eager-loading child
relationships. Writing code with ent is much easier because of everything is types, so you benefit
from code hinting from IDE - as well as avoiding typo when dealing with magic strings in gorm.
There is a significant learning curve because they are another systems to learn. In my opinion, it is
worth it compared to writing many-to-many by hand using sqlx or sqlc, but not if you do not need
dynamic queries or eager-loading.
If you need dynamic queries, a pure query builder like squirrel is excellent. Writing with it feels
close to writing a sql query. However, it doesn’t codegen so there are magic strings everywhere.
Also, usage of structs for equality and like are strange. sqlboiler is better, and you gain
code completion hints because it knows your database schema. Unfortunately, it falls short at
many-to-many relationship.
Finally, we have seen how powerful raw SQL is. The examples I have given are rather simple but if
you are required to write complex queries, you may find that it is hard to translate to an ORM, or
worse, not supported at all. In many cases, you often test that actual query before converting because
you want to make sure that it is working as intended. If you do not need dynamic query or eager-loading,
why not just use that working raw query? Everyone already knows sql anyway, and you already know
how to protect against sql injection, right?
For my first technical blog series, it took me a year of writing, researching, and re-writing many
times before I finally settle and feel like I can publicise. I hope you find these posts useful as
to they have to mine.
Comparison between popular go libraries and ORM for database access layer.
Typically, to make a transaction, we first start by calling BeginTx() method
in database/sql package which returns a Tx transaction struct.
Following the pattern from the Go blog at
https://go.dev/doc/database/execute-transactions,
we defer the rollback operation immediately after starting a transaction and ends with a commit.
This ensures that a rollback is always called even if any error or panic happens in the function.
If you carefully analyse the pattern above, you will notice that a rollback will happen after a commit.
Fortunately, if that transaction is already done, Go will ignore the rollback and does not make
another round trip to the database - Rollback() will be ignored if the transaction has been
committed as seen from the source code,
// rollback aborts the transaction and optionally forces the pool to discard
// the connection.
func (tx *Tx) rollback(discardConn bool) error {
if !atomic.CompareAndSwapInt32(&tx.done, 0, 1) {
return ErrTxDone
}
...
While knowing the pattern above is important, we want to know a couple of things when it comes to
creating a transaction across multiple SQL queries.
Reuse existing methods, collect, and run them in a transaction.
Adjust transaction isolation levels.
It would be nice if we can just reuse existing methods because why should we repeat ourselves if
the operations are the same, but we needed a transaction over them.
Understanding isolation level is essential when deciding which level we want our transaction to run
on. Isolation is the ‘I’ in ACID. There are four isolation
levels in SQL. In reality, there are only three in postgres as Read Uncommitted behaves like
Read Committed. You can read more about isolation level
in further details. The default in postgres is read committed.
This means that a SELECT query will only see data committed before the query began. In other
words, it will not see any in-progress uncommitted changes.
In this post, we will see how these libraries and ORMs fare with creating and using a transaction as
well as changing an isolation level.
Immediately defer Rollback(). Error is ignored because if rollback fails, it is not going to be
committed anyway.
defer tx.Rollback()
Call sql queries
var u db.UserDB
err = tx.GetContext(ctx, &u, getSQLQuery, userID)
Commits
if err = tx.Commit(); err !=nil {
returnnil, err
}
Note that it is possible to use the Begin() function in database/sql package. We use sqlx’s
Beginx() because we wanted to use GetContext() convenience function. Otherwise, Begin() is
perfectly fine.
To answer the two questions we set in the opening introduction, let us see how they do.
Notice that we cannot compose existing Get() and Update() methods together and apply
a transaction on them. We needed to either change the implementation of both methods to accept a tx
transaction variable, or make the method receiver to include tx transaction.
Moving on to changing transaction level, there are two ways of doing it.
Execute an sql query, for example tx.Exec('SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;')
Use sql.TxOptions{} struct from database/sql package.
There is no drama when setting the isolation level through an sql query:
In the second option, the built-in package database/sql provides a struct called sql.TxOptions
in which you can set the isolation level and read-only value.
However, there is a caveat. We are now using a method from database/sql instead of sqlx. That
means, we cannot use sqlx’s convenience scanning features like GetContext() that automatically
scans results into a Go struct.
sqlc
The pattern for transaction is similar to sqlx’s by using methods provided by database/sql
package with the addition of a constructor that accepts a transaction.
The secret sauce is qtx := pg.New(tx). Unlike sqlx, now we can compose existing GetUser() and
UpdateUser() methods with this tx variable transaction.
Just like sqlx, we can either use BeginTx() method to include isolation level or run an sql
query as usual.
squirrel
Like sqlx and sqlx, we need to use the underlying transaction struct of database/sql.
If you look at the code below, it is similar to how we did a Get operation, but in the query
builder, we tell squirrel to use tx transaction instead by passing it to the RunWith() method.
tx, err := r.forTx.Beginx()
if err !=nil {
returnnil, fmt.Errorf("fails to start transaction error: %w", err)
}
defer tx.Rollback()
rows := r.db.
Select("*").
From("users").
Where(sq.Eq{"id": id}).
RunWith(tx). // <- ensures that you use transaction.
QueryRowContext(ctx)
..._ = tx.Commit()
using RunWith() means we cannot compose existing methods. Fortunately, setting isolation is as
simple as executing the sql query.
gorm
There are two ways do perform database transactions, the first being like the pattern described in
the Go blog, and the second way is through anonymous function.
Anonymous Function
Transaction() accepts an anonymous function and provides transaction tx from gorm.
var u User
err := r.db.Transaction(func(tx *gorm.DB) error {
if err := tx.First(&u).Error; err !=nil {
return err
}
u.FirstName = req.FirstName
u.MiddleName = req.MiddleName
u.LastName = req.LastName
u.Email = req.Email
u.FavouriteColour = req.FavouriteColour
err := tx.WithContext(ctx).Save(&u).Error
if err !=nil {
return err
}
returnnil})
if err !=nil {
returnnil, err
}
return&u, nil
This approach means no composing of existing methods. To change isolation level, simply execute said
sql query.
Sqlboiler
Like above, sqlboiler can accept a transaction instead of normal sql.DB thanks to sqlboiler’s
methods accepting ContextExecutor interface.
tx, err := r.db.BeginTx(ctx, nil)
if err !=nil {
returnnil, fmt.Errorf("fails to start transaction error: %w", err)
}
defer tx.Rollback()
user, err := models.FindUser(ctx, tx, id) // pass in tx instead of sql.DB
if err !=nil {
returnnil, err
}
..._ = tx.Commit()
However, like squirrel, you cannot compose existing Get() and Update() methods. We would need
to refactor both Get() and Update() methods.
For example, we can add a new field in our database struct so that we can ‘save’ a transaction to
be used in our refactored Get() method.
type database struct {
db *sqlx.DB
exec boil.ContextExecutor // create a new field
}
Set the exec field with this transaction.
tx, err := r.db.BeginTx(ctx, nil)
r.exec = tx // Set our executor with this transaction
Our refactored Get() method now uses exec instead.
It begins by creating a transaction. Any errors that happen within the calling the anonymous
function fn(tx) will be rolled back. Otherwise, transaction is committed.
To use, we call Tx() function that returns an error. Within the business logic, we replace
all r.db with the tx parameter. Note that we needed to declare modesl.User outside of
this function, and assign the result we wanted with u = user.
func (r *database) TransactionUsingHelper(ctx context.Context, id int64, req db.UserUpdateRequest) (*models.User, error) {
u :=&models.User{}
err :=Tx(ctx, r.db.DB, func(tx *sql.Tx) error {
user, err := models.FindUser(ctx, tx, id)
if err !=nil {
return err
}
user.FirstName = req.FirstName
user.MiddleName = null.String{
String: req.MiddleName,
Valid: req.MiddleName !="",
}
user.LastName = req.LastName
user.Email = req.Email
user.FavouriteColour = null.String{
String: req.FavouriteColour,
Valid: req.FavouriteColour !="",
}
_, err = user.Update(ctx, tx, boil.Infer())
if err !=nil {
return err
}
u = user // assigns value we wanted with `u` outside of this `Tx()` function.
returnnil })
if err !=nil {
returnnil, err
}
return u, nil}
Ent
The documentation at https://entgo.io/docs/transactions
describes many ways to perform a transaction. The following method is what has been established:
In conclusion, creating a transaction is rather straight forward. We can use the established pattern
from https://go.dev/doc/database/execute-transactions
with all of these libraries and ORMs. However, only sqlc easily allows us to reuse existing Get()
and Update() methods by composing them and apply a transaction.
Comparison between popular go libraries and ORM for database access layer.
In this post, we will look at selecting records based on a column with multiple conditions. To keep
it simple, we will select users whose last names are ‘Donovan’ and ‘Campbell’.
In this post, we will look at how deleting a single record in a table works for these various
libraries and ORMs.
In general, this operation is simple because we only care about deleting and checking for an error.
We cannot pass in a slice into sqlx because the sql driver does not understand Go slice. Instead,
given a series of IDs, we need to create a series of ? depending on the length of that slice. In
sqlx, a helper function called sqlx.In() has to be called before doing the main query.
err = r.db.SelectContext(ctx, &dbScan, "SELECT * FROM users WHERE last_name IN (?)", f.LastNames...)
The above code won’t work. First, SelectContext() only accepts a slice of interface, not a
slice of strings. Next, there is only one question mark placeholder. Given that we are using
Postgres, we need to use dollar placeholders instead.
So the above query won’t generate a valid sql query. The reason is I think sqlx touches your query
as little as possible. So it needs to be a valid sql query first.
query, args, err := sqlx.In("SELECT * FROM users WHERE last_name IN (?)", f.LastNames)
The In() method expands the ? bindvar to the length of f.LastNames slice. By default, it turns
into a series of ?. For postgres, we must yet do another transformation so that it uses dollar signs.
Doing dynamic queries is tricky with sqlc. First of all, there is no support for a WHERE IN()
support for mysql from sqlc. There is an open issue for this.
I suppose there is a dodgy way by extrapolating the number of ? placeholders
mysqlQuery := fmt.Sprintf(`SELECT * FROM users WHERE last_name IN (?%v);`, strings.Repeat(",?", len(f.LastNames)-1))
Only issue here is that f.LastNames slice variable need to be sanitized because it originates from
user input and thus potentially can cause a sql injection.
Anyhow, since we are demonstrating for Postgres, we can make use postgres array! When writing the SQL
query, we declare that we accept an array of text for last_name using last_name = ANY($1::text[].
SELECT id, first_name, middle_name, last_name, email, password, favourite_colour
FROM users
WHERE last_name =ANY($1::text[])
The code that gets generated by sqlc now accepts an array using pq.Array
We use sq.Eq{} struct by giving it the column name we want, and then the slice of arguments.
Using sq.Eq{} may be unintuitive because we would expect to use WHERE IN wording somewhere.
Moreover, sq.Eq{} struct expects a map of string with any type as its value. Since we supply a
list of strings, squirrel will generate a WHERE IN sql statement. We will later see in the
Get section where sq.Eq{} can accept a single
integer value to get one record.
By default, squirrel will create question mark placeholders. Since we are using postgres, we need
dollar placeholders instead. We can add a method to each query builder or, we can avoid repetition
by setting it during repository initialisation.
Squirrel does not have StructScan() or SelectContext() convenience method like sqlx, so we need
to do manual scanning.
var dbScan []*userDB
for rows.Next() {
var u userDB
err := rows.Scan(&u.ID, &u.FirstName, &u.MiddleName, &u.LastName, &u.Email, &u.Password, &u.FavouriteColour)
if err !=nil {
returnnil, err
}
dbScan = append(dbScan, &u)
gorm
Gorm will happily take a slice for your WHERE IN(?). It even correctly use the correct dollar
placeholders because we have imported "gorm.io/driver/postgres" somewhere in our code.
err = r.db.WithContext(ctx).
Where("last_name IN ?", f.LastNames).
Find(&users).
Error
Unlike sqlx, you do not need to put a parentheses around the question mark placeholder.
sqlboiler
Sqlboiler has a WhereIn() query modifier which takes column_name IN ?. In spite of using this
method, you still need to type in IN ? as a string in the argument. I imagine the API can be
simpler by accepting something like WhereIn(last_name, args...).
The variadic arguments requires an interface type instead. Since sqlboiler is not generic yet, we
need to transform our string slice into a slice of interface{}.
import"github.com/samber/lo"args := lo.Map(f.LastNames, func(t string, _ int) any {
return t
})
sqlboiler will take the dollar placeholder without a parentheses.
all, err := models.Users(
//qm.WhereIn("last_name", args...), // Does not work. Needs IN operator
//qm.WhereIn("last_name IN ($1, $2)", "Donovan", "Campbell"), // Is what we want
qm.WhereIn("last_name IN ?", args...), // instead, just give it a `?`.
).
All(ctx, r.db)
ent
Doing a Where IN(?,...) in ent is as easy as Gorm, but with the added advantage of having no magic
strings whatsoever.
LastNameIn() function is generated by the ent cli based on the schema we have defined. If we look
at its function signature, LastNameIn(vs ...string) predicate.User, we can clearly see that it
requires none or a slice of strings.
Like all others, by default ent will add edges{} to the response even when you did not load any
relationship.
Ent is again the easiest to use amongst all with Gorm coming in close second. There’s too much work
involved in sqlx. Squirrel is quite ok. Usage of a sq.Eq{} struct is interesting but scanning can
be a major headache. Sqlboiler syntax can be a little more friendly.
Comparison between popular go libraries and ORM for database access layer.
Often when you are listing a resource, a client may want to perform various filter operations and
sorting. They may want to retrieve all addresses in a specific postcode, or sort the users by
last name followed by first name. A common way of making this request is by passing them using query
parameters in a GET operation in the URL request.
For example, GET /api/user?email=john@example.com only returns user record with john@example.com
as its email. GET /api/users?sort=first_name,asc sorts users by first name in ascending order. We
can add multiple columns to sort by adding more sort key: GET /api/users?sort=first_name,asc&sort=email,desc.
For pagination, we can either define offset and limit or use the convenience page key:
GET /api/users?page=2. Please note that there is a huge penalty LIMIT and OFFSET when you are
retrieving records where the offset is in the millions. See Why You Shouldn’t Use OFFSET and LIMIT For Your Pagination.
ORDER BY also must be added in all LIMIT and OFFSET.
Before going further into the implementation, we add a convenience function in our handler(controller)
layer that receives client requests. This function parse requests by its query parameters.
Here, we declare what field(s) we accept for filtering the users. Then we use url.Values.Get() method
to retrieve them. We decided that we can put multiple names separated by a comma on one query parameter,
so we have a helper function that can turn a string seperated by a comma into a slice of strings.
package db
type Filter struct {
Base filter.Filter
Email string FirstName string FavouriteColour string LastName []string}
funcFilters(v url.Values) *Filter {
f := filter.New(v)
lastNames := param.ToStrSlice(v, "last_name")
return&Filter{
Base: *f,
Email: v.Get("email"),
FirstName: v.Get("first_name"),
FavouriteColour: v.Get("favourite_colour"),
LastName: lastNames,
}
}
The filter/base.go file which is shared by all, handles parsing of query parameters. To use it,
we call the package’s db.Filters() function and pass in URL query from handler’s http.Request.
func (h *handler) List(w http.ResponseWriter, r *http.Request) {
f := db.Filters(r.URL.Query())
Then we inject the f variable down to our data access layer.
sqlx
First we show a dodgy way of doing dynamic filtering by a field by building the strings ourselves.
Care must be taken that we do not concatenate users’ input into the query itself because it will be
vulnerable to sql injection. Instead, we must use placeholders. In the subsequent sqlc section, we
will show a better way - using conditional sql query.
1. Filter By Email
We start by declaring a couple of sql clauses. We select all records from users table and limit it
to the first 30 records.
So what we want is basically the following query but with dynamic WHERE according to what is
passed in the URL query parameter.
SELECT*FROM users WHERELOWER(email) =?ORDERBY id LIMIT30OFFSET0;
Note that there are spaces in the strings because we need some spacing when we combine the strings.
selectClause :="SELECT * FROM users "// notice the spaceat the end?paginateClause :=" LIMIT 30 OFFSET 0"//andat the beginning?
Then we start appending LOWER(email) = ? clause to our empty whereClauses string. We had to use
LOWER() function of postgres because our schema is not case-insensitive. Unlike mysql, a database
can be built using ci (case-insensitive) collation e.g. ...collate utf8mb4_unicode_ci;. We also
use ? placeholder instead of using $ placeholder because we cannot be sure of the order when
filtering by column is optional. We can always rebind the whole query with sqlx’s Rebind() method.
Once whereClauses concatenation are completed, we concatenate to the full query.
Then loop filters.Base.Sort to concatenate column and order string along with arguments.
Looping filters.Base.Sort gives the flexibility to client to determine which column order comes
first.
for col, order :=range filters.Base.Sort {
sortClauses += fmt.Sprintf(" %s ", col)
sortClauses += fmt.Sprintf(" %s ", order)
}
Concatenating strings make me feel uneasy. Is this vulnerable to sql injection? You can try hitting
the api with:
All in all, there is a lot of boilerplate to perform these three types of operations. Care must be
taken, so we do not allow any sql injection.
sqlc
There is a terrible way to do it in sqlc by writing all permutations of columns.
We do not really want to write them all because 2 columns means there are
2! == 4 permutation, for example:
Query without filtering
Query with first_name filtering
Query with email filtering
Query with both first_name and email filtering.
If we have 3 columns, 3 factorial is 6. And 4 factorial is 24 permutations!.
So we try with conditional SQL query:
-- name: ListDynamicUsers :many
SELECT id, first_name, middle_name, last_name, email, password, favourite_colour
FROM users
WHERE (@first_name::text=''OR first_name ILIKE'%'||@first_name ||'%')
AND (@email::text=''OR email =LOWER(@email) )
ORDERBY (CASEWHEN@first_name_desc::text='first_name'THEN first_name
WHEN@email_desc::text='email'THEN email
END) DESC,
(CASEWHEN@first_name_asc::text='first_name'THEN first_name
WHEN@email_asc::text='email'THEN email
END),
id
OFFSET@sql_offset LIMIT@sql_limit;
For example, whenever first_name is present, then the whole (@first_name::text = '' OR first_name ILIKE '%' || @first_name || '%')
line will be true.
Doing order is tricky when we want to decide whether we are sorting a column by ascending or
descending order. We use CASE ... THEN ... END to decide whether we want to include the clause or
not.
One thing missing is WHERE and ordering by favourite colour in which sqlc doesn’t play well with
pgx driver as far as I know.
Since we store sort information in a struct, we need to loop them and assign to the generated
ListDynamicUsersParam struct
p := ListDynamicUsersParams{
SqlOffset: int32(f.Base.Offset),
SqlLimit: int32(f.Base.Limit),
}
iflen(f.Base.Sort) > 0 {
for col, order :=range f.Base.Sort {
if col =="first_name" {
if order =="ASC" {
p.FirstNameAsc = col
} else {
p.FirstNameDesc = col
}
}
}
}
Obviously this only handles first_name. You need to repeat the col check for each column you want
to sort. One thing I haven’t managed to do is conditional query on an enum column.
3. Pagination
Not much drama with pagination. We simply provide the values from the base filter struct.
p := ListDynamicUsersParams{
SqlOffset: int32(f.Base.Offset),
SqlLimit: int32(f.Base.Limit),
}
As you can see, using conditional greatly reduces the boilerplate as compared to our sqlx example.
It is just a matter of getting the initial sql query correct first.
This also means that we could have used conditional sql for sqlx too.
squirrel
Since squirrel is a query builder, it should shine with dynamic queries.
Filter by Email
Chaining the methods that we want is exactly how we build the query.
Note that requesting with ?first_name=jake won’t yield any result because the case does not match
since Gorm does not perform LOWER() to the input or ILIKE to the column. To fix this, we cannot
use struct map, instead we need to use Where() and Or() methods.
In conclusion only sqlc did not pass all functionalities we required like dealing with dynamic
filtering and case-insensitive user input. Concatenating string in sqlx is potentially error-prone
(and dangerous!). Order of methods are important in Gorm. Squirrel is straightforward. Finally, both
sqlboiler and ent offer type safe query and easy query building.
Comparison between popular go libraries and ORM for database access layer.
In this post, we will look at listing users with all their addresses. Both users and addresses
tables are joined with a pivot table, user_addresses, which holds the foreign key of each of
users and address table primary key.
As the erd suggests, a user can have many addresses, and an address can belong to many users.
There are many ways to do this. The most straight away method (what most ORM does) is to perform
a query on each of the related tables.
Get 30 records of users
For each user, get the IDs of the address from the pivot table
Get all records of addresses from the IDs retrieved in the previous step.
Begin attaching address to users.
ORMs often do this automatically for you. Writing sql manually means you have to do all the
steps above.
The other way is to perform left joins on the tables, starting from users, and ends with addresses.
Left join is important because if we perform an inner or right join instead, if a user do not have
an address, that user record will not be returned. While doing left joins, alias, especially on IDs
must be set to prevent name conflict. In my opinion, this method is a poor fit when doing a
many-to-many operation. The following method is better.
Finally, it is possible to use array_agg (for postgres) function or group_concat for mysql/mariadb.
You write the least amount of Go code but requires you to have a sufficient amount of SQL knowledge
to craft the correct query.
sqlx
We will take a look at two methods, method 1 which by which is by doing a query on each table, and
the third method, which is relying on a single query. I will omit the second method because it is
much more complicated than method 1.
Method 1: The Long Way
If you look at the full source code, it is 2 pages long.
So, I will only include relevant snippets here.
Starting with sql queries, we try to limit number of users to 30.
To find out the address of each user, we get that relationship from the pivot table. For an array
of user IDs, we can always do a SELECT DISTINCT u.id FROM users u LIMIT 30;. But this is an
additional query while we can extract the IDs from query #1.
-- #2
SELECTDISTINCT ua.user_id AS user_id, ua.address_id AS address_id
FROM"addresses" a
LEFTJOIN"user_addresses" ua ON a.id = ua.address_id
WHERE ua.user_id IN (?);
We then get all address IDs, pass into the following query, and execute.
-- #3
SELECT a.*FROM addresses a
WHERE a.id IN (?);
Notice that the two last queries uses ? instead of $1. It relates to sqlx’s ability (or inability)
to properly turn array values for IN operator. So what w can do is to use the In() function to
expand into a slice of arguments.
sqlx.In accepts an array of interface but executing QueryContext() expects int8.
Only using ? placeholder sqlx won’t complain about types.
Once we perform the first sql query, we can the result into a custom struct
([]*UserResponseWithAddressesSqlx), one with address field.
type UserResponseWithAddressesSqlx struct {
ID uint`json:"id,omitempty"` FirstName string`json:"first_name"` MiddleName string`json:"middle_name,omitempty"` LastName string`json:"last_name"` Email string`json:"email"` Address []AddressForCountry `json:"address"`}
var all []*UserResponseWithAddressesSqlx
for users.Next() {
var u userDB
if err := users.Scan(&u.ID, &u.FirstName, &u.MiddleName, &u.LastName, &u.Email); err !=nil {
returnnil, fmt.Errorf("db scanning error")
}
all = append(all, &UserResponseWithAddressesSqlx{
ID: u.ID,
FirstName: u.FirstName,
MiddleName: u.MiddleName.String,
LastName: u.LastName,
Email: u.Email,
})
}
We retrieve all user IDs and get its associated addresses with the second sql query. We need to scan
and hold the data with another struct so that wen use it to find the associations later.
type userAddress struct {
UserID int`db:"user_id"` AddressID int`db:"address_id"`}
Then get all address IDs and execute the third sql query. Scan the results into a new address struct -
it needs the db struct tag.
The final step is to loop through all array of structs and attach their associations
for _, u :=range uas {
for _, user :=range all {
if u.UserID ==int(user.ID) {
for _, addr :=range allAddresses {
if addr.ID ==uint(u.AddressID) {
user.Address = append(user.Address, AddressForCountry{
ID: addr.ID,
Line1: addr.Line1,
Line2: addr.Line2.String,
Postcode: addr.Postcode.Int32,
City: addr.City.String,
State: addr.State.String,
})
}
}
}
}
}
Note that if a user record do not have any address, the value for address key will be null,
instead of an empty array.
So you need to remember to initialize the addresses for a user
all = append(all, &UserResponseWithAddressesSqlx{
ID: u.ID,
FirstName: u.FirstName,
MiddleName: u.MiddleName.String,
LastName: u.LastName,
Email: u.Email,
Address: []*AddressForCountry{}, // instead of leaving it empty
})
In my opinion, this is too much code for just a simple two tables plus a pivot table to deal with.
Imagine having to eager-load 7 tables deep. That is a nightmare.
Method 3: The SQL way
So let us take a look at using the third method, which is using both array_agg and row_to_json
and see if it is anything simpler. If you take a look at the SQL query below, it looks similar to
the query we have done for 1-many, but we are now joining three tables:
SELECT u.id,
u.first_name,
u.middle_name,
u.last_name,
u.email,
u.favourite_colour,
array_to_json(array_agg(row_to_json(a.*))) AS addresses
FROM addresses a
JOIN user_addresses ua ON ua.address_id = a.id
JOIN users u on u.id = ua.user_id
GROUPBY u.id;
The relevant bits are that the JOIN operation starts from the ’lower’ aggregated records
(addresses table) and we work our way up to the users table.
With array_to_json(array_agg(row_to_json(a.*))), we turn each row in addresses as a json
array. After performing the left joins, we select user columns we want and finally group them by
user ids. The result is we only get users that have at least one address.
Notice that this SQL query omits users that do not have any addresses. To include them, simply
change the JOIN above to RIGHT JOIN.
One caveat, just like we showed in one-to-many example is that we need to parse the json array from
database back to a Go struct if we want to play around with it. If you don’t we can simply scan into
json.RawMessage.
sqlc
We already know the exact SQL query we need to perform this M2M query so, it is similar to method 3
of sqlx, but with less boilerplate. We do not need to manually scan database results to a struct
because they are all generated for you, but you still need to extract IDs from each. For method 1,
it only takes a page long to perform many-to-many compared to almost 2 pages long for sqlx.
You still need to manually attach address to a user like sqlx. Also, you need to remember to
initialize addresses for a user like above instead of leaving it empty.
Upon sqlc compilation, it generates a method that you can simply use:
dbResponse, err := r.db.ListM2MOneQuery(ctx)
However, since it outputs a struct consisting of sql.Nullstring for middle_name and an enum
for favourite_colour, we want to convert them into another struct
Like sqlx and sqlc, method 3 is going to have far fewer boilerplate than method 1. The long method 3
is uninteresting because we have already shown how to do it with sqlx. Let us see how this query
builder fare.
rows, err := r.db.
Select(
"users.id",
"users.first_name",
"users.middle_name",
"users.last_name",
"users.email",
"users.favourite_colour",
"array_to_json(array_agg(row_to_json(a.*))) AS addresses",
).
From("addresses AS a").
InnerJoin("user_addresses ON user_addresses.address_id = a.id").
InnerJoin("users ON users.id = user_addresses.user_id").
GroupBy("users.id").
QueryContext(ctx)
One look, and you can see that this is almost a one-to-one translation from the SQL query we wanted
into Go code. There are a few differences to the approach we made in the 1-to-many section.
First of all, in the 1-to-many section, the whole database response is in JSON format. Here, only
one column is in JSON format, namely the last addresses column.
At first, I wanted to make array_to_json(array_agg(row_to_json(a.*))) AS addresses statement into
its own select using s := r.db.Select("array_to_json(array_agg(row_to_json(a.*)))") and then chain
with FromSelect(s, "addresses") but that did not work.
The inner join argument here is interesting. We pass one string only, unlike other ORM in other
languages where they can be separated with commas. Here it can take optional arguments. That means
we can do something like this…
InnerJoin("user_addresses ON user_addresses.address_id = a.id AND a.id = ?", 7).
… and it will only return records on the user_addresses join where address ID is equal to 7.
The trickiest part is the scanning, like in one-to-many section, we have to construct a Go struct
specifically for this query. The first six columns for users table are clear. addresses
on the other hand is actually a JSON response - so we need to implement the Scanner interface.
The amount of code needed to be written is also greatly reduced compared to sqlx, sqlc, and squirrel
so far. The key is to use Preload() method. What is not obvious is what magic string you need to
supply to it. The answer is the name of the field itself - it has to match. For example, User
struct has Addresses in its field, so we supply the string Addresses inside Preload().
type User struct {
... Addresses []Address `json:"address" gorm:"many2many:user_addresses;"`}
We also need to tell Gorm the pivot table that is used to link between users and addresses table.
It is done by using a struct tag gorm:"many2many:user_addresses;".
Gorm has no code generation like sqlboiler and ent. Instead, it relies on structs (and struct tags)
as its point of reference.
sqlboiler
Unfortunately I cannot find an easy way to eager load many-to-many relationships with sqlboiler.
Current recommendation is to fall back to raw sql queries.
ent
Like its one-to-many operation, ent shines at loading relationships.
We use the same pattern as what we did with one-to-many - {{ With{{Model}} }} pattern.
If a user has no address, the edges key will only contain an empty object.
Ent makes 3 separate sql queries, just like what we have done for sqlx, and gorm.
In my opinion, the API is very straightforward and there isn’t a way to get it wrong. Everything
is statically typed with no interface{} anywhere which makes it predictable. Only downside I can
think of is you need to spend time getting the relationship in the model schemas correctly.
In conclusion, using raw sql is too much work when it comes to loading many-to-many relationships.
Imagine if we want to load 7 tables deep, it’d be a nightmare. While using sqlc improves upon sqlx
by reducing a good deal of boilerplate, it still pales in comparison to using an ORM. You need to
be careful with struct tag with Gorm, and it was not obvious that you had to use a field name for
Preload(). Ent does not have Gorm’s issues as everything is typed. You will need to learn to using
With... pattern though which isn’t a big deal.
Comparison between popular go libraries and ORM for database access layer.
In this post, we will look at getting a list of countries along with its addresses.
There are three ways of loading this kind of relationship:
Perform one sql query on both tables
Perform a left join from countries to addresses table,
Use array agg (for postgres) function or group concat for mysql/mariadb.
Option one is what most ORM does. They query the parent table, then get its IDs. With those IDs,
they query child table relationships. The more relationships you require, the more sql queries you
make. Each child relationships are then attached to the parent based on the foreign keys that
has been defined. As a result, you get a struct where you can walk through from parent to child
table.
Using joins can be an easy way of getting all data in a single query. You potentially return more
data than option number one when a child record belongs to many parent table. Furthermore, the type
of joins is important. If you have made an INNER JOIN between parent and child table, and that
child table record is NULL, you may end up losing parent table record in your final result.
Joining a number of tables with millions of records can result in huge memory usage. This is because
in SQL order of execution, it first
joins the tables in memory before selecting relevant columns. Even though you make a single SQL
query, you need to loop through the results and scan child record to the correct parent record.
In my opinion, tracking the relationships are hard and error-prone.
Finally, we have an option to use native functions to aggregate child record results to their
related parent tables. There is array agg for postgres and group concat for mysql or mariadb.
For this, I create a view called country address that aggregates addresses to its country.
CREATEVIEW country address asselectc.id, c.code, c.name,
(
selectarrayto json(array agg(rowto json(addresslist.*))) asarrayto json
from (
select a.*from addresses a
wherec.id = a.country id
) addresslist) as address
from countries ASc;
Running select * from country address; will give id, code, name, and address in a JSON
format.
To get everything in a JSON format, you may query with select row to json(row) from (select * from country address) row;.
However, you still need to parse this JSON response back to a Go struct.
const GetWithAddresses2 = "select row to json(row) from (select * from country address) row"func (r *database) Countries(ctx context.Context) ([]*CountryResponseWithAddress, error) {
var resp []*CountryResponseWithAddress
rows, err := r.db.QueryContext(ctx, GetWithAddresses2)
if err !=nil {
returnnil, fmt.Errorf(`{"message": "db error"}`)
}
defer rows.Close()
for rows.Next() {
var i CountryResponseWithAddress
err = rows.Scan(&i)
if err !=nil {
returnnil, err
}
resp = append(resp, &i)
}
return resp, nil}
GetWithAddresses2 query is a statement that queries the view that we have created. On top of that,
we used row to json() function that tuns the whole response as a json format. Before we go ahead,
let us take a step back and define our Go struct.
type CountryResponseWithAddress struct {
Id int`json:"id,omitempty"` Code string`json:"code,omitempty"` Name string`json:"name,omitempty"` Addresses []*AddressForCountry `json:"address"`}
To figure out how to form this struct, we need to know the response coming from the database.
The key (pun intended) here is to look at the JSON key, namely id, code, name, and
addresses. That is how we decide to name the fields in the CountryResponseWithAddress struct.
Go will automatically figure out which json key maps to a field.
Notice that the last field needed to be plural Addresses instead of singular address. We can
override this by using a db struct tag - which uses reflection.
Because the whole response is in a JSON format, we need to tell the runtime on how to handle and parse
the result to a Go struct.
To achieve this, we implement one of database/sql interface called Scanner. It contains one method
called Scan(). So we create our own implementation of scanner interface
with Scan(src any) error by unmarshalling into JSON.
// From standard library `database/sql` package
type Scanner interface {
Scan(src any) error}
// CountryResponseWithAddress is our own custom struct that reflects the result we want
type CountryResponseWithAddress struct {
Id int`json:"id"` Code string`json:"code"` Name string`json:"name"` Addresses []*AddressForCountry `json:"address"`}
// Scan implements Scanner interface using our CountryResponseWithAddress struct
func (m *CountryResponseWithAddress) Scan(src any) error {
val := src.([]byte) // []byte is an alias of []uint8
return json.Unmarshal(val, &m)
}
This means, every time err = rows.Scan(&i) is called, it will go into this Scan(src any) error
method of CountryResponseWithAddress instead of the default Rows struct from database/sql
package.
We can try the second approach by using a struct like this
If no field name or alias conflicts, we should be able to attach the addresses to its country by
looping through the records keeping track of the country ids.
And of course, we need to perform two queries for the first method. Then we need to loop over
result from addresses and attach them to a country or countries by looking at the foreign keys.
sqlc
In sqlc, we do not have to worry about writing boilerplate because the code is auto generated from
the sql query we already know.
-- name: CountriesWithAddressAggregate :many
selectrowto json(row) from (select*from country address) row;
So only three lines are needed to get the correct result.
However, sqlc uses json.RawMessage. If you need to play around with the returned database records,
you need to unmarshall this JSON response to a Go struct, an example in which I show in the squirrel
section below.
squirrel
The obvious way to do this is like in approach number 1. Query each table, and then attach relevant
address (if exists) to a country.
But since squirrel is a query builder, we are more interested to find out how building the such
query looks like. Let us take a closer look at the query.
selectrowto json(row) from (select*from country address) row;
First of we have a row to json postgres function that takes up row as its argument. The second
part is we select everything from a view called country address and is aliased to become row.
To build this query using squirrel, we have to build each of these to different parts:
s := r.db.Select("* from country address")
rows, err := r.db.
Select("row to json(row)").
FromSelect(s, "row").
QueryContext(ctx)
First, we select the view and store in a variable (s) - this is the select * from country address
part. Then we do a Select("row to json(row)"), and chain it to a FromSelect() method.
Once this is done, we can scan it to either simply a raw JSON message or a custom Go struct.
var items []json.RawMessage
for rows.Next() {
var rowToJson json.RawMessage
if err := rows.Scan(&rowToJson); err !=nil {
returnnil, err
}
items = append(items, rowToJson)
}
Using a custom Go struct is much more elaborate. First you have to figure out the correct struct
for this JSON payload:
type CustomGoStruct struct {
Id int`json:"id"` Code string`json:"code"` Name string`json:"name"` Address []struct {
Id int`json:"id"` Line1 string`json:"line 1"` Line2 string`json:"line 2"` Postcode int`json:"postcode"` City string`json:"city"` State string`json:"state"` CountryId int`json:"country id"` } `json:"address"`}
And then make sure to implement Scanner interface for this struct
So far, getting this to work is the hardest. The code above looks
deceptively simple but to get to this point is not.
It is true that we simply call Preload() method to load child relationship, but before we dive
further into the code, let us see how we declare our structs for our tables.
type Country struct {
ID int`json:"id"` Code string`json:"code"` Name string`json:"name"` Address []Address `json:"address" gorm:"foreignkey:country id"`}
The struct declares that we have three columns. To define the relationships, one cannot think of it
like an sql schema. Here, it is telling that a ‘Country’ has many Address, and denoted by
[]Address slice. Thus, the Address field is a reference to the addresses table.
Next, take a look at Address struct:
type Address struct {
ID int`json:"ID,omitempty"` Line1 string`json:"line 1,omitempty" gorm:"Column:line 1"` Line2 string`json:"line 2,omitempty" gorm:"Column:line 2"` Postcode int32`json:"postcode,omitempty" gorm:"default:null"` City string`json:"city,omitempty" gorm:"default:null"` State string`json:"state,omitempty" gorm:"default:null"` CountryID int`json:"countryID,omitempty"`}
This almost looks alright except that CountryID field should have been a foreign key to
countries table. But just by looking at the struct above, there’s no indication that it is a
foreign key. By Gorm convention, CountryID field will become country id column in this address table.
Let us take a second look at the following snippet:
One must be careful with the Find() method with the type you are putting into it.
We give it a slice of address pointers, ([]*Countries). If you do not, for example, giving it an
Country type will return a single record!
Also, we made a mistake in the code above even though Go compiler returns no error. The Find()
finisher is called too soon and ignore Select(). We are lucky because we were doing SELECT *
anyway. But if we were doing SELECT id in the code above for example, it will be ignored.
var country Country
// country will be filled with the first record in the database.
err := r.db.WithContext(ctx).
Preload("Address").
Select("*").
Find(&country).
Error
There is no enforcement on the type that can be accepted inside Find(), not surprising
because it accepts an empty interface. Gorm uses a lot of reflection to get to the type.
You can also omit the Select("*") builder, and it will work the same! It is forgiving but on the
other hand loses explicitness when it comes to building a query.
sqlboiler
1-N in sqlboiler is more verbose than what you would expect from what an ORM would do. However,
everything is typed - no magic strings anywhere which prevents any typo.
It starts with models.Countries(). In its argument, we use the generated package to load the
relationship by its string, denoted by models.CountryRels.Addresses. The method All() ‘finisher’
executes the query.
func (r *database) Countries(ctx context.Context) ([]*db.CountryResponseWithAddress, error) {
countries, err := models.Countries(
qm.Load(models.CountryRels.Addresses),
qm.Limit(30),
).
All(ctx, r.db)
if err !=nil {
returnnil, err
}
var all []*db.CountryResponseWithAddress
for , country :=range countries {
resp :=&db.CountryResponseWithAddress{
Id: int(country.ID),
Code: country.Code,
Name: country.Name,
Addresses: getAddress(country.R.Addresses),
}
all = append(all, resp)
}
return all, err
}
So why are we looping countries in the next few lines?
The reason is the generated model.Country struct relationship (or edge) has - as its struct tag.
This means when we return the result to the client, the marshalled json would not contain any
addresses.
type Country struct {
ID int64`boil:"id" json:"id" toml:"id" yaml:"id"` Code string`boil:"code" json:"code" toml:"code" yaml:"code"` Name string`boil:"name" json:"name" toml:"name" yaml:"name"` R *countryR `boil:"-" json:"-" toml:"-" yaml:"-"`// this edge won't be returned to client
// because json is tagged with -
L countryL `boil:"-" json:"-" toml:"-" yaml:"-"`}
For this reason, we need to create a new struct, and copy them over if we want to send the child
relationships to client.
ent
In ent, we use the With... method to eager load a relationship. Each model in a json response
will contain an edges key no matter if there is any relationship(s) or not.
To define the relationship, or ’edges’ in ent’s lingo, you write an Edges() method on User
struct.
// Edges of the User.
func (User) Edges() []ent.Edge {
return []ent.Edge{
edge.From("addresses", Address.Type).Ref("users"),
}
}
It is compulsory to set a link back to user from an address:
// Edges of the Address.
func (Address) Edges() []ent.Edge {
return []ent.Edge{
edge.To("users", User.Type),
}
}
All we need to do after the schema is defined is to run go generate ./... and we practically need
one line is needed that says query all Country with its Address relationship.
In this post, we have seen each library and ORM vary wildly in the approach between them. Sqlx
is quite normal with normal scanning. Sqlc on the other hand, removes all boilerplate present in
sqlx. Squirrel documentation is contained inside its source code. You cannot be sure of Gorm’s
method chaining order and its struct key. Sqlboiler is similar to squirrel in its ease of query
building but its addresses child records are not serialized by default.
Ent however, shines over other libraries and ORMs. If you have a good sql expertise,
sqlc is pretty awesome. Otherwise, ent’s eager loading API is a breeze to use.
We pass a &User{} struct which indicated gorm that it is deleting this users table. Gorm
magically figure out the name of the table you want using
the name of the struct.
sqlboiler
In sqlboiler, deleting is opposite to gorm when compared to doing an update operation. Here, sqlboiler
deletes a record through query building which means
two queries are made. Delete() method must be done on the models.User struct.
Comparison between popular go libraries and ORM for database access layer.
In this post we will see a simple update of a resource by using its ID. We will try to perform an
UPDATE <TABLE> SET <COLUMN1>=<VALUE1> etc, if not, we simply retrieve the item first, set to new
values, and then save the record.
We only show how to do a full PUT updating instead of a PATCH, where a patch means we only
update certain fields only, leaving other columns untouched.
As a good practice, we scan user’s request to a custom UserUpdateRequest struct. Then we hand
over this struct to our database access layer.
Our request struct looks like the following. We are making a PUT request instead of a PATCH.
That means we have to include the changed value as well as all other fields in our update request to
the database. If we only include one field, other fields will be zeroed out.
So, the client must use GET, then update what is necessary, and finally call a PUT endpoint.
The struct to receive client request will look like this. We use json.NewDecoder(r.Body).Decode(&request)
to parse PUT json payload to a Go struct. These json struct tag helps with determining with json
key should map to a Go field.
Although the client did a GET prior to this PUT request, we still need to do another Get()
because we need to retrieve hashed password. If we straight away assign new values, then password
column will be empty since client never had this information! Also, we cannot trust the client sends
complete data for this PUT request.
Finally, we call our own Get() method to return the updated record with the updated updated_at
column value. Three separate sql queries means this is a good candidate to perform a transaction on.
Named Query
Sqlx has a feature called named queries. To use it, we
need to modify our sql query with colon character. Good thing is this is still a valid postgres
query.
const UpdateNamed = "UPDATE users set first_name=:first_name, middle_name=:middle_name, last_name=:last_name, email=:email WHERE id=:id;"
Then we create a new struct with db struct tag to tell which field belongs to which column.
type updateNamed struct {
ID int64`db:"id"` FirstName string`db:"first_name"` MiddleName string`db:"middle_name"` LastName string`db:"last_name"` Email string`db:"email"`}
Finally, we can call NamedExecContext() method without worrying about the order.
Scanning is a pinch in expense of writing more boilerplate beforehand.
sqlc
Unlike sqlx, we do not have to worry about the order because we are filling in the update to the
generated struct made by sqlc generate. Like sqlx, we need to retrieve the record before
updating the values.
In many cases, we would want to perform a transaction over these three sql queries - something that
which we will cover in the transaction section of this blog series.
Once we retrieve the record from database, we begin to update the field that we want.
The Save() method can be chained to Error to propagate the error up to our handler. It is easy
to forget this because it is not compulsory and Go compiler won’t complain about it.
sqlboiler
Updating in sqlboiler, like gorm, behaves like common ORM; you have to find the record, and then
update desired fields.
Note that we omit setting up a password, so that it will not be changed. Since middle_name is
an optional field, you have to you use null.String{} struct to fill in the new value. We ignore
the first return value with underscore unless you want to know the number of rows being affected.
Important: You need to find the record before updating. If you straightaway call Update() and not
setting a password, that password field will be deleted from the database!
Comparison between popular go libraries and ORM for database access layer.
In this post, we will look at how these libraries and ORM deal with fetching a single record given
an ID. There should not be any drama as we only be doing a simple query as follows:
For scanning to work, this struct needs db struct tag annotated on each field at the moment.
middle name is nullable, so we declare the type to be sql.NullString to allow value to be
scanned as either a string or a null value.
type userDB struct {
ID uint`db:"id"` FirstName string`db:"first name"` MiddleName sql.NullString `db:"middle name"` LastName string`db:"last name"` Email string`db:"email"` Password string`db:"password"`}
Note that usage of that db struct tag will cause reflection to be
used. There is a way to avoid it by matching the field names with database column names. For
example First Name to match against first name database column. Title Case naming style
is not a convention in Go though.
One last thing is the way we handle error. It is possible that the client requests for a user ID
that do not exist, or have been removed from the database. So we want to return appropriate message
and correct HTTP status. We can use error.Is() function to compare the err value against built
in error provided in the sql package.
sqlc
While inflexible, sqlc continues to impress with its API usage. GetUser() method is generated for us
by annotating the sql query with the following the name that we want and how many records it is
returning.
-- name: GetUser :one
SELECT id, first name, middle name, last name, email, favourite colour
FROM users
WHERE id = $1;
To use, we simply call the generated method. The rest are simply error handling and DTO transform.
Select() and From() method on the other hand are ok because their method signatures clearly
states what type they require.
We then finish off with a finisher QueryRowContext() that returns a RowScanner interface. That
means, we have to manually scan and take care of the column orders.
var u db.UserDB
err := rows.Scan(&u.ID, &u.FirstName, &u.MiddleName, &u.LastName, &u.Email, &u.Password, &u.FavouriteColour, &u.UpdatedAt)
if err !=nil {
if errors.Is(err, sql.ErrNoRows) {
return&db.UserResponse{}, &db.Err{Msg: message.ErrRecordNotFound.Error(), Status: http.StatusNotFound}
}
log.Println(err)
return&db.UserResponse{}, &db.Err{Msg: message.ErrInternalError.Error(), Status: http.StatusInternalServerError}
}
gorm
Gorm is relatively simpler by using a basic First() method to obtain a record by its id.
We must remember to chain Error after First() method. This is easy to forget because it is not
compulsory.
Remember that in the previous post where Find() can also accept a slice of users? First() method
can also accept a slice. So be careful with what you are putting into it. The number of records
being returned is not determined by the method we use, but by the type given to Find() or First().
func (r *repo) Get(ctx context.Context, userID int64) (*User, error) {
var user User
err := r.db.WithContext(ctx).
// First() also can accept a `var user []*User` which can return more than one record!
First(&user, userID).
Error
if err !=nil {
if errors.Is(err, gorm.ErrRecordNotFound) {
return&User{}, &db.Err{Msg: message.ErrRecordNotFound.Error(), Status: http.StatusNotFound}
}
log.Println(err)
return&User{}, &db.Err{Msg: message.ErrInternalError.Error(), Status: http.StatusInternalServerError}
}
return&user, nil}
The second argument of First() accepts a variadic interface. So unless you refer to gorm’s website
for a documentation, you cannot infer what type it needs.
As our User model already has - json struct tag on password, we do not have to worry it
leaking to client.
type User struct {
ID uint`json:"id"` FirstName string`json:"first name"` MiddleName string`json:"middle name"` LastName string`json:"last name"` Email string`json:"email"` Password string`json:"-"`}
sqlboiler
You do not have to write much boilerplate to get a single item in sqlboiler. FindUser() argument
types are laid out specifically and the name helps into inferring what you need to supply.
Discounting error handling, it also a one-liner for ent.
u, err := r.db.User.Query().Where(user.ID(uint(userID))).First(ctx)
if err !=nil {
if gen.IsNotFound(err) {
return&gen.User{}, &db.Err{Msg: message.ErrRecordNotFound.Error(), Status: http.StatusNotFound}
}
log.Println(err)
return&gen.User{}, &db.Err{Msg: message.ErrInternalError.Error(), Status: http.StatusInternalServerError}
}
return u, nil
No copying to a new struct is needed since the password field is already made sensitive.
Getting a specific resource is a lot simpler than creating and listing them. All of them have their own
convenience method to scan database result to a Go struct.
In sqlx, listing an array of json looks similar to how sqlx creates a record. We use QueryxContext()
method that allows us to use StructScan() that makes scanning easier - no longer do you need to
type out all the field names.
const list = "SELECT * FROM users LIMIT 30 OFFSET 0;"func (r *database) List(ctx context.Context) (users []*UserResponse, err error) {
rows, err := r.db.QueryxContext(ctx, List)
if err !=nil {
returnnil, fmt.Errorf("error retrieving user records")
}
for rows.Next() {
var u userDB
err = rows.StructScan(&u)
if err !=nil {
returnnil, errors.New("db scanning error")
}
users = append(users, &UserResponse{
ID: u.ID,
FirstName: u.FirstName,
MiddleName: u.MiddleName.String,
LastName: u.LastName,
Email: u.Email,
UpdatedAt: u.UpdatedAt.String(),
})
}
return users, nil}
We collect the records as an array of UserResponse. This is because we do not want to expose the
password to the client.
This is true for returning users’ details, but sometimes you want to play
around with that protected field and only converting to UserResponse at handler layer, just before
returning that data to client. So instead of scanning to UserResponse struct, you should scan into
a struct with a Password field.
text[] data type
Since we work with postgres, we should also explore into one of its data type not present in mysql,
sql server, and oracle, array. We basically want to select tags of a specific user.
In the users schema, we have a text[] data type. It is interesting to see how we can select this
kind of data type.
To make it simple, we want to select its tags based on user ID:
SELECT tags FROM users WHERE users.id = $1
The result coming from the database for the column tags is now in binary instead of text (data
type is text[]). So in the code, data coming from database is in bytes (bytes is an alias for
uint8) but, we are scanning the result into a slice of string. So, we cannot simply scan using
&values because it is a mismatched data type - *[]string vs []uint8. What we do instead is to
use pq.Array(), which helps us into choosing the optimum data type for scanning.
That’s it. Only 3 lines, or 1 line, however you may want to look at it!
Since in the query we omit selecting the password, this prevents that field from leaking. So I
cheated a bit. If you require to play around with the password value, you will need to remember
to transform to a userResponse struct.
And since we now use methods instead of writing raw SQL, it suddenly becomes easier to create
dynamic query as you will see in the dynamic list
section.
Squirrel requires a finisher which will then return a sql rows and a possible error.
gorm
Listing user records looks deceptively simple. It looks like a normal query builder but there are
many ways it can go wrong. Have a look at this:
At a glance, there isn’t anything obviously wrong with the code above. In fact, if you run the code,
you will get a result with no error. However, there are subtle mistakes or quirks compared to the
query builder we have seen so far. You need to:
Tell the model you are asking for a list with []*User
But you can pass in a *User instead, and it will return 1 record.
The Find() method accepts an interface, so it will happily accept anything whether a slice or a single item (or something totally different).
var user User
err = r.db.WithContext(ctx).Find(&user).Limit(30).Error` <- passing `&user` returns one record.
You are doing an implied select operation, selecting all fields using *. If you want to select just a few fields:
Gorm does not provide a constant for each of database field’s name.
Instead of passing a struct, you pass a slice of string. Need to refer documentation because
method’s signature does not help - its signature is saying it accepts a query interface and
a list of arguments?! Select(query interface{}, args ...interface{}) (tx *DB)
You can also pass strings to Select() and it will give the same output even if it doesn’t conform to method signature and the IDE telling you are wrong.
// this
err := r.db.WithContext(ctx).Select([]string{"id", "first_name", "last_name"}).Find(&users).Limit(30).Error
// also works, look at below screenshot
err := r.db.WithContext(ctx).Select("id", "first_name", "last_name").Find(&users).Limit(30).Error
first argument is a query and the rest are args as expected, but it still returns the same result
If you want to do a ‘WHERE’ clause, you can use a Where() method. But you can also put the
User struct as a second parameter to the Find() method!
On the upside, you do not have to worry about leaking password to client because in the User
model, we set the json struct tag to -. Thus, no copying to a new struct is needed.
type User struct {
ID uint FirstName string MiddleName string LastName string Email string Password string`json:"-"`}
WithContext() is optional.
In Go, we tend to use context for cancellation, deadline and timeout. WithContext() is optional
which means we can lose these features by forgetting to chain it.
‘Finisher’ method is optional, and the order is important.
Finisher methods like Find(), First(), and Save() are optional when building a query.
err = r.db.
WithContext(ctx).
Find(&users). // <- called to early! Subsequent `Limit()` will be ignored, so it'll return all records in the database.
Limit(30).
Error
If you do not include them, Gorm will do nothing, and thus will not return either an error or any result.
The order when you call those finishers are also important. If you call it too early, Gorm will
ignore subsequent methods. For example, the examples I have shown so far has Limit() called
after Find(). That means, Gorm will ignore anything after Find() finisher and return all records
in the database! If you scroll back to point number 2, you may have noticed that in the code
screenshot, it returns 32 records (everything I have) in the database instead of returning 10
records. Unlike other libraries, calling other methods after a finisher is invalid.
Using the API requires a bit of discovery and careful reading of its documentation since its method
signature does not help.
In my opinion, thanks to many pitfalls Gorm has, it is certainly the hardest to use so far.
sqlboiler
In sqlboiler, listing a resource is done with All() method. To limit the records, you have to use
the query modifier (qm) package.
sqlboiler is a lot nicer than gorm for sure. You avoid any magic string which makes it more type-safe
compared to gorm. It will complain if you do not provide a context. You cannot ignore the error
return unless you explicit does so with underscore, _.
But, a fair bit of discovering is needed to know all qm helpers - {{model}}Where, and
{{model}}Columns patterns. For example, in my opinion it is more intuitive to use
models.Users().Limit(30).All(ctx, r.db) to limit instead of using a query modifier.
Password field is automatically generated, and you cannot set it to private. So you will need to
remember to perform data transform object (DTO) before returning to client - as you should always do.
ent
In ent, it is similar to sqlc, but we do not have to worry about copying the fields to a new struct
without password because that field is already protected (or in ent’s lingo, sensitive) from json
marshalling.
Limiting the number of records is done with Limit() builder method instead of using another
package like sqlboiler.
The advantage with ent, like gorm, is we can continue using that sensitive field but, we are assured
it will not be leaked to client. However, the API is a lot more intuitive and looks more like an ORM
in other language.
In conclusion, sqlc and ent were the easiest to use. sqlc is pretty much a one-liner once you have
written the correct sql query. ent gives the best API for query building. In both, we do not have to
worry about leaking the password field to the client. However, you cannot customise sqlc queries
at runtime.
While the examples here are very simple - list 30 records of the users at most - real world use case
are usually more complex. We will see how we eager load a relationship and in the dynamic list
section, we will explore at parsing query param for sorting and pagination.
Before going to those sections, we will finish of WHERE IN(?) and the rest of CRUD stuff.
Comparison between popular go libraries and ORM for database access layer.
In this post, we compare and contrast how these libraries and ORMs handle a record insertion.
As a standard approach to all example in these blog series, our controller accepts and parses
client request to a custom ‘request’ struct, and if required, parses query parameter(s). We hash the
password and together with CreateUserRequest we try to insert to database. Then the struct
is passed down to our data access layer.
type CreateUserRequest struct {
ID uint`json:"id"` FirstName string`json:"first_name"` MiddleName string`json:"middle_name"` LastName string`json:"last_name"` Email string`json:"email"` Password string`json:"password"`}
All CRUD operations are done in crud.go files of each of the libraries and ORMs directories.
You should perform validation in production. In our case, we skip this part to keep this blog series
focused.
In sqlx, we call ExecContext() to perform an insertion. It requires a context, an SQL query and
its arguments. In this example, we use QueryRowContext() which not only performs the insertion,
but we can obtain the newly inserted data thanks to using postgres’ RETURNING clause.
Care needs to be taken that the order of your arguments must match with your sql query. Any order
mismatch will cause an error. That means if column order has been changed, you will have to check
your Go code manually since this library or compiler does not warn you.
Similar story in the scanning database values into Go code. Scanning is tedious because not only you
need to get the order right, but you also need to know what the required fields are required to be
scanned by looking at the sql query. For example, middle_name is nullable, which means the value
can be either null or a string. For that reason, we need to scan the value into something like
sql.NullString.
type userDB struct {
ID uint`db:"id"` FirstName string`db:"first_name"` MiddleName sql.NullString `db:"middle_name"` LastName string`db:"last_name"` Email string`db:"email"` Password string`db:"password"`}
Also, the userDB struct is a new custom struct created
specifically for scanning the values into a Go struct. We use a db struct tag for each field. It
can potentially use reflection to know which database column maps to
which struct field by looking at the struct tag. The value you give to the db struct tag must
match with the field name you have in the database.
Note that we are returning userDB type that has a password field. We should not expose this
field to the client. We have already omitted scanning password field into userDB struct. But
a good discipline is to have a struct for each db scanning and client response. In this
example, we make a data transform object (DTO) from a db struct by copying into a UserResponse
struct that does not have a password field.
To use sqlc, we put all of sql queries in an .sql file and tell sqlc to generate from that file.
You only need to give each of the query a name and how many records it returns. For example:
The name that we want our method is CreateUser and it only returns one record. Once sqlc.yaml
is properly configured, we run
$ sqlc generate
And the generated codes are created in query.sql.go.
func (q *Queries) CreateUser(ctx context.Context, arg CreateUserParams) (User, error) {
row := q.db.QueryRowContext(ctx, createUser,
arg.FirstName,
arg.MiddleName,
arg.LastName,
arg.Email,
arg.Password,
arg.FavouriteColour,
)
var i User
err := row.Scan(
&i.ID,
&i.FirstName,
&i.MiddleName,
&i.LastName,
&i.Email,
&i.Password,
&i.FavouriteColour,
)
return i, err
}
sqlc automatically generates Go code containing the arguments to QueryRowContext() as well
as the scanning. To use, we call this CreateUser() method with the provided struct to fill in
the parameters CreateUserParams.
Notice how the order no longer matters because we are filling in the parameters in a struct. But
with any schema change (column ordering, creation, etc), you will have to re-run sqlc generate.
Note that CreateUserParams generated by sqlc requires the optional field middle_name to be
declared in sql.NullString and we have to tell that it is valid! The Go documentation in
database/sql package says that
NullString implements the Scanner interface so
it can be used as a scan destination:
var s NullString
err := db.QueryRow("SELECT name FROM foo WHERE id=?", id).Scan(&s)
...if s.Valid {
// use s.String
} else {
// NULL value
}
What I often do is I use my IDE to automatically set all required fields I need to fill in:
Overall, sqlc does look less error-prone than sqlx. You still need to copy over the fields to
UserResponse like sqlx to prevent leakage of password field as usual.
squirrel
Writing squirrel feels like writing a hand-rolled query but uses Go methods. The methods reflect
their sql counterpart. However, you still need to write magic strings for columns and tables names.
Scanning order is also important. There are no generated helper struct to insert the parameters.
Creating using gorm looks similar to sqlx. But chaining the Error is not compulsory, WithContext() too.
So it is easy forget to call it.
In Gorm, we need to declare a struct for Gorm to scan into. No special struct tag is needed. Here,
only json struct tag is used to do two things; 1. decide the json key for each field and; 2. Do not
serialize Password field ( annotated with a - struct tag) and return to user.
This User struct
is also the same struct used for gorm’s auto migration. Since Gorm tends to use a single model struct
for everything, it is important to keep this password field from leaking to the client. Of course,
a good practice is to have separate struct for database and client response so that we can control
what the client sees.
type User struct {
ID int`json:"id"` FirstName string`json:"first_name"` MiddleName string`json:"middle_name"` LastName string`json:"last_name"` Email string`json:"email"` Password string`json:"-"`}
Gorm has a feature of adding a gorm.Model field that automates creation of ID,created_at, and
updated_at timestamps.
Inserting a record also looks similar to sqlc and gorm. Like sqlx, you need to use the user struct
(models.User) generated by the library. Like sqlc, assigning middle_name is awkward.
Here the third parameter of Insert() is something you can choose whether you want
sqlboiler to infer which column to insert, or manually set them:
Infer the column list, but ensure these columns are not inserted
Greylist
Infer the column list, but ensure these columns are inserted
Then, you use Insert() method of the User struct to perform an insertion.
You do not have to worry if sqlboiler does a RETURNING clause or not because it will fill in
the ID to the User struct for you.
Since Password field is not annotated with - struct tag, you will need to copy over the fields
to UserResponse struct like sqlx above.
ent
Instead of using a struct to set the values, ent uses a builder pattern. The choice to give an
empty string or null to middle_name depends on which method you choose.
func (r *database) Create(ctx context.Context, request db.CreateUserRequest, hash string) (*gen.User, error) {
saved, err := r.db.User.Create().
SetFirstName(request.FirstName).
SetNillableMiddleName(&request.MiddleName). // Does not insert anything to this column
//SetMiddleName(request.MiddleName). // Inserts empty string
SetLastName(request.LastName).
SetEmail(request.Email).
SetPassword(hash).
Save(ctx)
if err !=nil {
returnnil, fmt.Errorf("error saving user")
}
return saved, nil}
Ent uses a code-first approach (defines models and relationships using code as opposed to using
database as a single source of truth), so before using ent, we need to define the fields and
relationships(edges) with a methods.
Notice that password field is made sensitive, which means, the json output will not contain the
password. This means, you no longer have to worry about forgetting to copy the values to a new
struct just to hide password value.
Like all ent output, there is an additional field called edges added to client response. There
isn’t a way to turn off edges key from ent’s output, so you will need to transform to a new
response struct before returning to the client.
If table columns order keeps changing, then both sqlx and squirrel will be a nightmare because
scanning order needs to keep track with your database schema. Others do not suffer this issue.
All of them return an updated model with its ID after insertion which is great especially when we
want to return that record back to client.
There is an awkward setting value to a nullable column in both sqlc and sqlboiler request.MiddleName) != ""
sqlx, squirrel and gorm transparently handles this nil value.
Ent gives an option to set middle_name column to be nullable (SetNillableMiddleName(&request.MiddleName)) or
empty string (SetMiddleName(request.MiddleName)). There’s a bit of a learning curve especially to
knowing how to define the relationships between the tables.
Comparison between popular go libraries and ORM for database access layer.
There are a multitude of ways to interact with a SQL database in Go. The most obvious path is to
simply use database/sql package from the standard library plus a database driver. It is easy to use
and can be sufficient to meet all of your requirements. Using raw SQL directly means you can
leverage what you already know, SQL, and craft complex queries in many ways that an ORM may not
support. However, retrieving (scanning in Go lingo) results from database is verbose and can be
tedious - something that alternatives shine. This series of posts will show how different popular
libraries and ORM available of Go are used. They are sqlx, sqlc,
squirrel, gorm,
sqlboiler, and ent.
This post is only an introduction to these packages. I will briefly touch on each of them on what
it is and database operations that we are going to test with. In the next posts, we will cover
common use cases for each. Full source code is available at https://github.com/gmhafiz/golang-database-library-orm-example.
This is the most popular library for purists and often the most recommended one. It requires you to write your own SQL queries,
yet it has some convenience method to make scanning results to a Go struct easier.
sqlc
Like sqlx, you also write your own SQL, but sqlc generates a lot of Go boilerplate that you
would otherwise have to write if you were using sqlx. You only need to install sqlc once, and set a
config file. Then for each of your query, it needs to be annotated with a desired method name, and
the expected number of record - one or many. Everytime you run sqlc generate, it will create
Go methods from your sql queries that both queries (or execute), and scans.
squirrel
update(12 July 2022)
Squirrel is an sql query builder. Unlike both sqlx and sqlx, you do not need to manually write
sql queries. Instead, squirrel provides helper functions like Select(),
Where(), From(), as well assq.Eq{} for equality.
gorm
Gorm is among the earliest and the most popular ORM library that still actively maintained till today.
Instead of writing SQL queries, you write a Go struct with correct struct tags for each of your
tables and gorm will handle creation of the tables in the database. Further tuning is done using
struct tags. Among many ORMs, this is an example of code-first library. Query building is fairly
decent - a lot of (type) guessing is needed because of interface[} usage everywhere, and order or
methods are important. Scanning database results however is easy thanks to
reflection.
sqlboiler
Sqlboiler is opposite in the approach from gorm where it is a database-first approach. You provide
a config file (sqlboiler.toml) with your database credentials, and it will learn the schema and
generate custom-tailored ORM specific to your database, including all structs for all CRUD
operations. As a result, you can rely and on generated methods and constants which mean you hardly
need any magic strings.
Like sqlc, you must remember to re-generate to update this ORM. It this is a
good idea to put this command in your build pipeline.
ent
Ent is the newest entry in the list, used to be part of facebook community repository, now it is in
its own. It has the most features and the easiest ORM to use.
It uses a code-first approach. You write Go methods to define a table fields and its relationships
which can take some learning curve. Like both sqlc and sqlboiler, you must remember to re-generate
the ORM.
You get a more statically typed ORM compared to sqlboiler. Handling one-to-many or
many-to-many is easy. Query building however, can be a lot more verbose.
Spectrum
With the many libraries and ORMs available for Go, it can be hard to visualise where do these
tools stand from, ranging from pure sql (hand-rolled) queries to traditional ORM.
Above is an illustration comparing the mentioned libraries in a spectrum between close-to-the-metal,
or raw SQL queries to full ORM capabilities.
Both sqlx and sqlc are very close to the standard database/sql library with sqlc inches ahead.
Anything you give into these libraries are sent to the wire almost without any changes.
I put squirrel in the middle where it is the most builder-ish library amongst all.
Ent has to be the most ORM-ish amongst all, so it is placed on the furthest right. Sqlboiler is not
too far off because it still requires some raw SQL in some cases.
That leaves gorm, a weak-ish ORM (full of interface{} everywhere!) but with excellent query
builder capabilities.
Operations
The blog series will demonstrate several operations that I think most applicable to a common CRUD
Go api. The operations that we will compare and contrast are:
Simple CRUD operation
We test two things:
We will look at how easy/hard it is for create, read, update, and delete operations for users table.
Given an array of IDs, how it deals with WHERE IN(?, ...)
1-to-Many queries
We list all addresses of a particular country.
Many-to-many queries
Since a user can have many addresses, and an address can hold many user, we look at how we can
list them all.
Dynamic list filter from query parameter
Pagination is a common use case. We will see how these libraries and ORMs deal with limiting the
number of records being returned.
Say the client want to sort our users list by last name in
ascending order. An example url query will look like this:
We may want to return a list with specified property. For example, we want to return users
whose last name is ‘Campbell’. Going further, we may want to combine several properties, say
last name is ‘Campbell’ and favourite colour is ‘blue’. A URL can look like this:
Nowadays, safety against sql injections should not be an issue to any developers. Correct use of
placeholders and prepared statement protect against this security vulnerabilities. Sanitisation of
user input will also help in preventing this. Yet, we will still look over how they behave when we
purposely try to give malicious user input.
Schema
We have a simple schema but still allows us to query one-to-many and many-to-many relationships.
A country has many addresses
A user can have many addresses; and an address can hold many users. These tables are joined by
the pivot user_addresses table.
To make things interesting, we have nullable columns denoted with ? in the erd above, so we can
see how serialization to json works.
The enum is an interesting case especially when it comes to libraries or ORM that generate codes,
will they create type for that enum or not? If yes, how do they handle it when Go does not have a
strong enum support.
We will also see how we prevent password field from being serialized and sent to the client.
That is something that we do not want to leak. Generally, we want to make a data transform so that
we can control what the client receives. This transform technique also prevents accidental leaking
of data when we create new columns in a table. Nevertheless, we will see if these libraries or ORMs
has any mechanism to prevent such sensitive data leak.
Files
In the repository, each library/orm are placed inside /db folder. Each folder under /db contains
a file for each section in this blog series such as crud.go for CRUD stuff. Each folder contains
helper functions such as database.go for library initialisation, handler.go for controller/handler
that receives a request, transform into internal request struct, call data access layer, then finally
transform into a JSON response.
Outside of this folder, we have several files shared by all. A model.go contains any database structs.
Any query param or JSON payload are parsed by filter.go.
A quick note on the handler layer - real
world API must have validation performed on client requests; but is omitted for simplicity.
First up, we see how common CRUD operations are done, starting with Create:
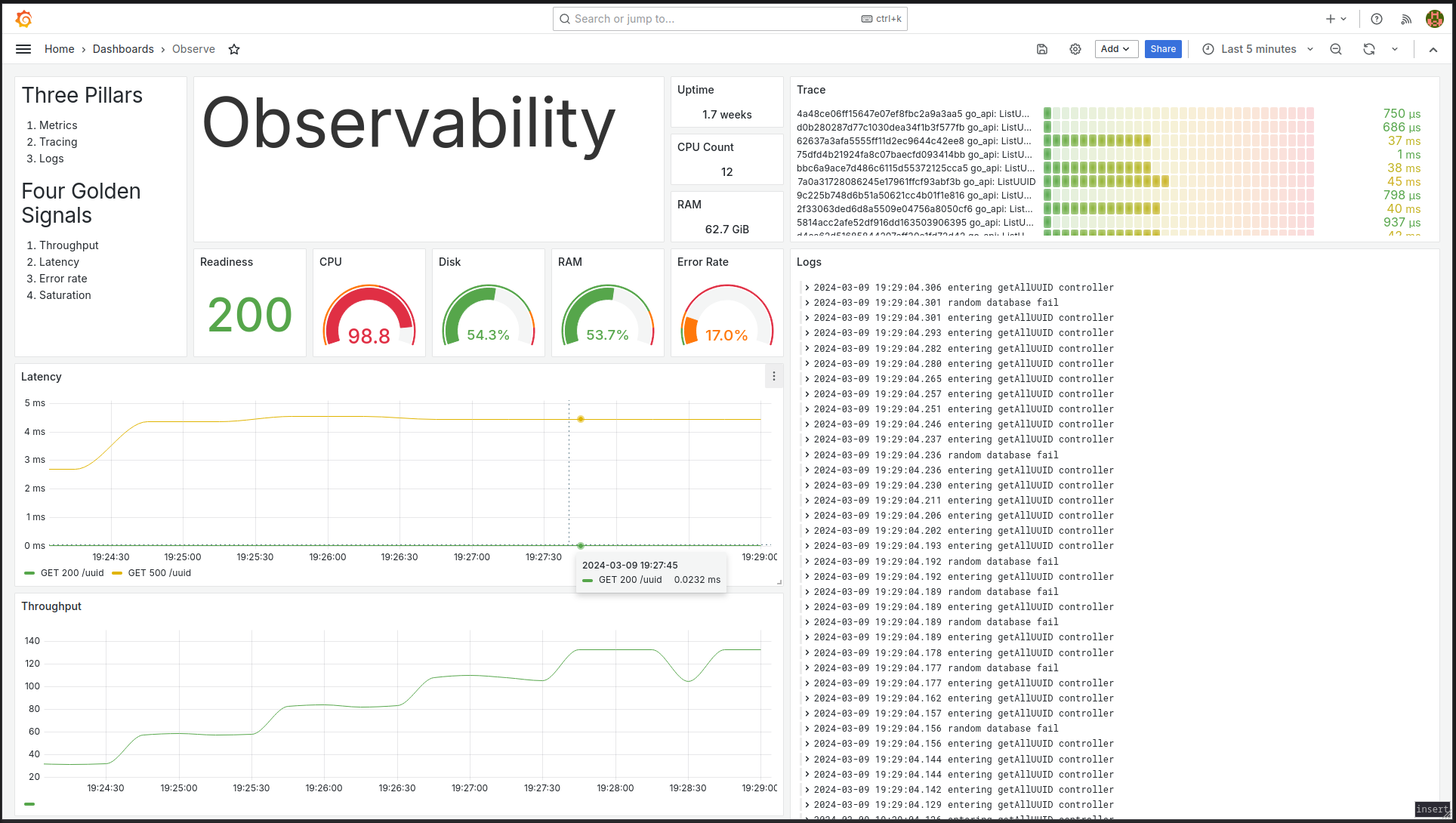 Figure 2: Single pane of view to observability.
Figure 2: Single pane of view to observability. Figure 3: Have you ever missed the error lines you are interested with in spite of your shell script skills?
Figure 3: Have you ever missed the error lines you are interested with in spite of your shell script skills?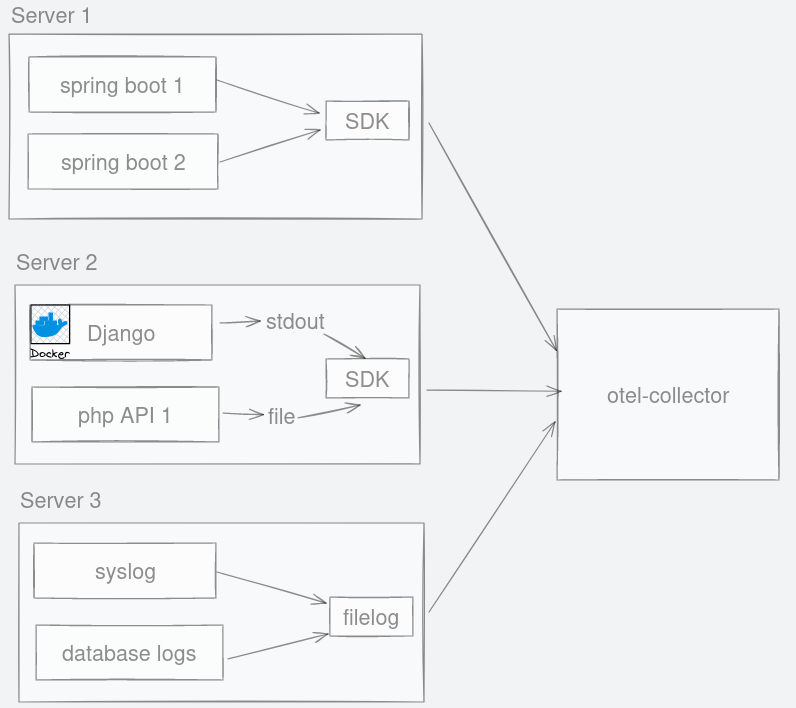 Figure 4: No matter where logs are emitted, they can be channelled to otel-collector.
Figure 4: No matter where logs are emitted, they can be channelled to otel-collector.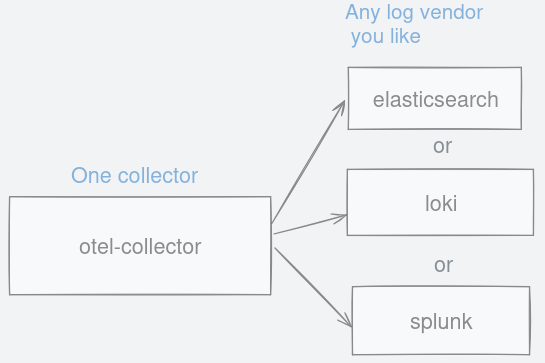 Figure 5: Choose between any logging backend you like as long as they support otlp format.
Figure 5: Choose between any logging backend you like as long as they support otlp format.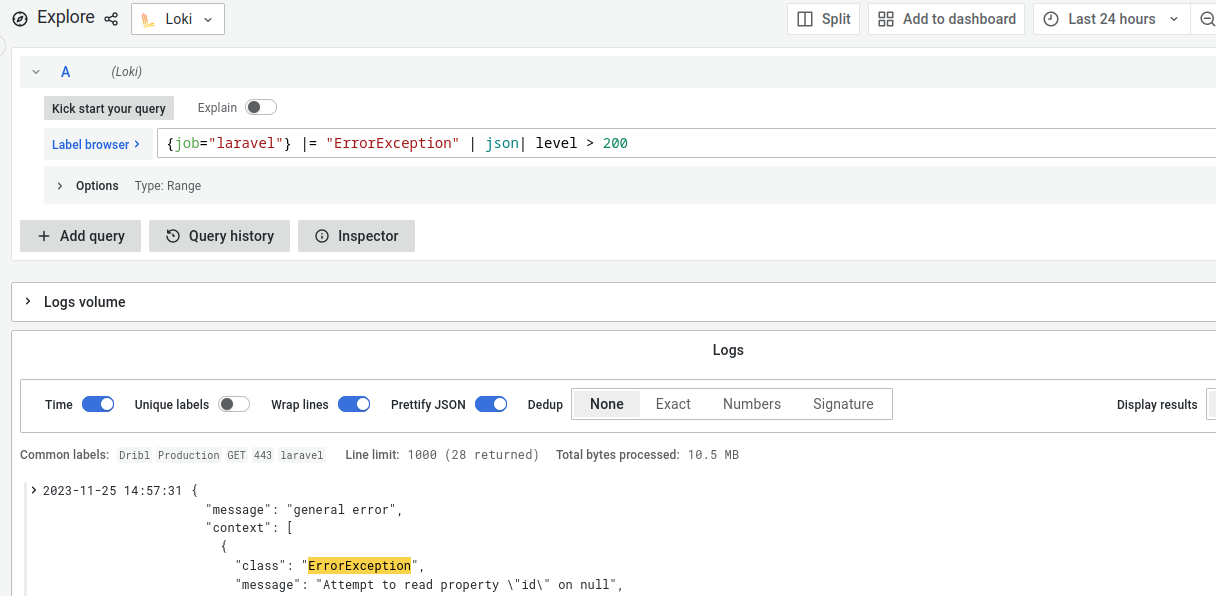 Figure 6: Great user interface that allows searching using a readable query language.
Figure 6: Great user interface that allows searching using a readable query language.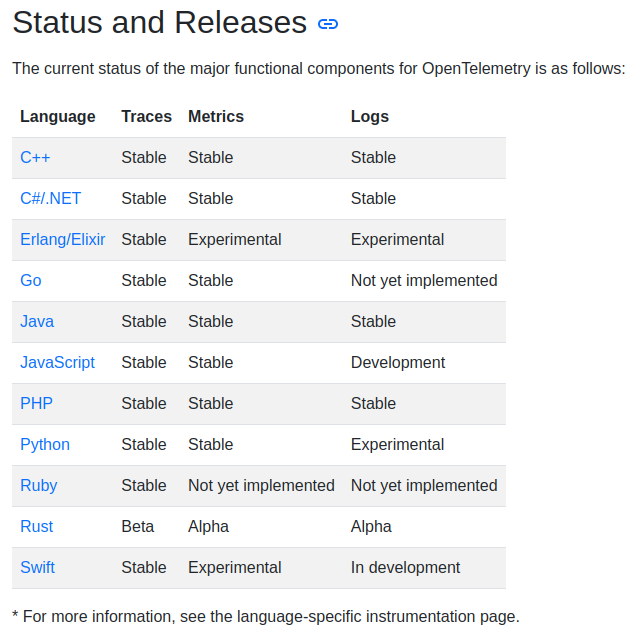 Figure 7: https://opentelemetry.io/docs/instrumentation/#status-and-releases
Figure 7: https://opentelemetry.io/docs/instrumentation/#status-and-releases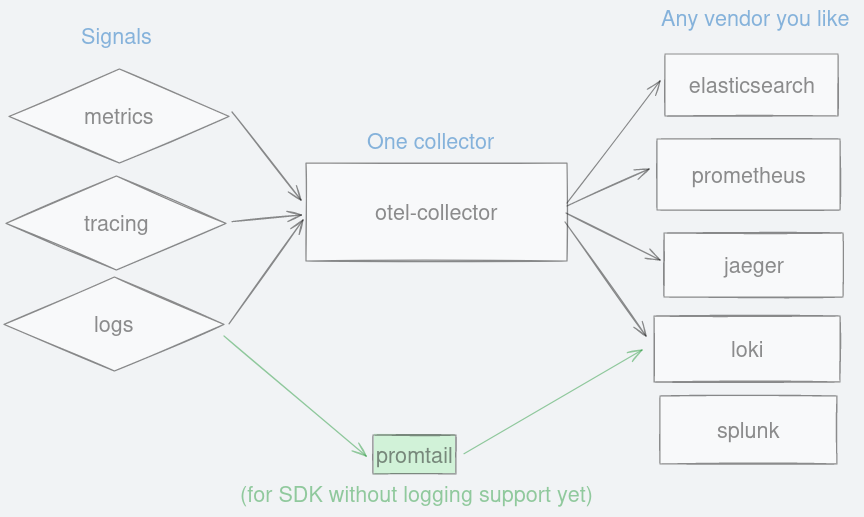 Figure 8: Alternative pathway for pushing logs into your backend using promtail.
Figure 8: Alternative pathway for pushing logs into your backend using promtail.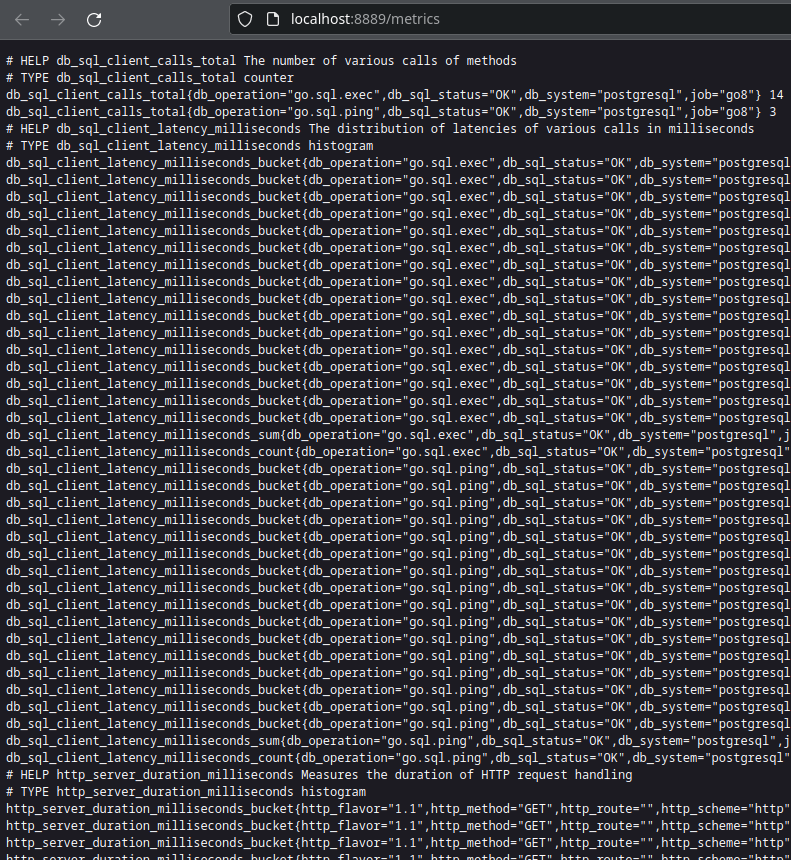 Figure 9: Raw metrics data collected by otel-collector.
Figure 9: Raw metrics data collected by otel-collector. Figure 10: Formula to finding out the rate is simply the delta over time.
Figure 10: Formula to finding out the rate is simply the delta over time.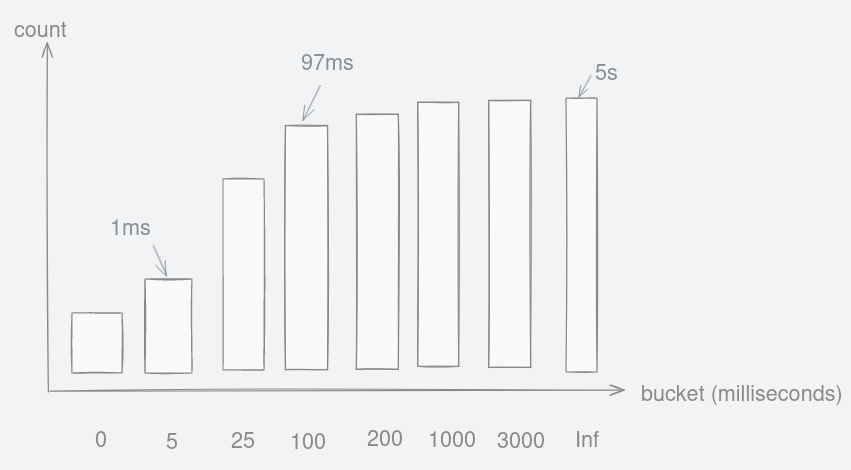 Figure 11: Hypothetical cumulative histogram that stores request duration into buckets.
Figure 11: Hypothetical cumulative histogram that stores request duration into buckets.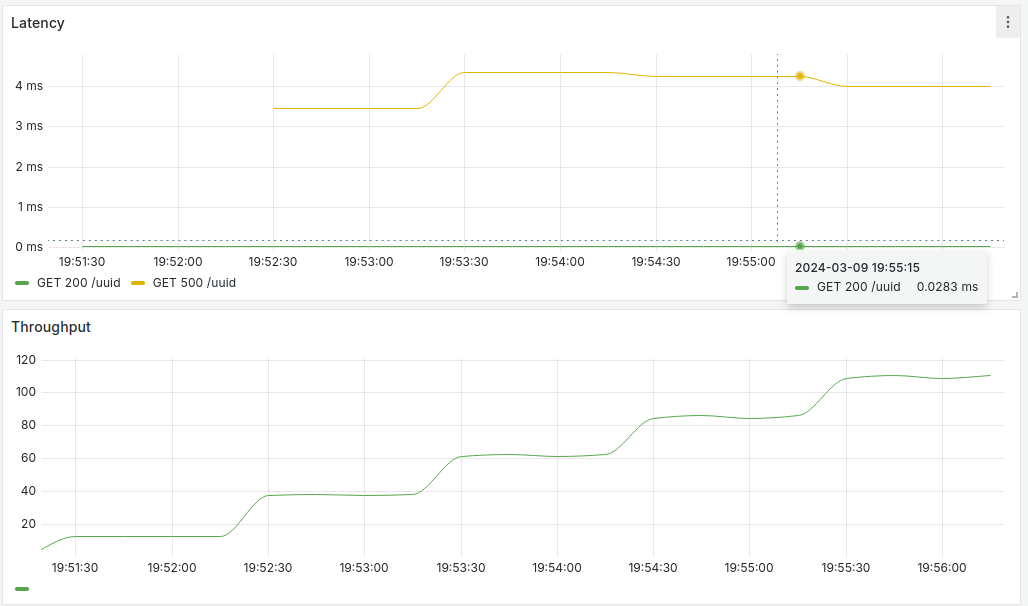 Figure 12: Line charts showing latency and throughput for /uuid endpoint.
Figure 12: Line charts showing latency and throughput for /uuid endpoint.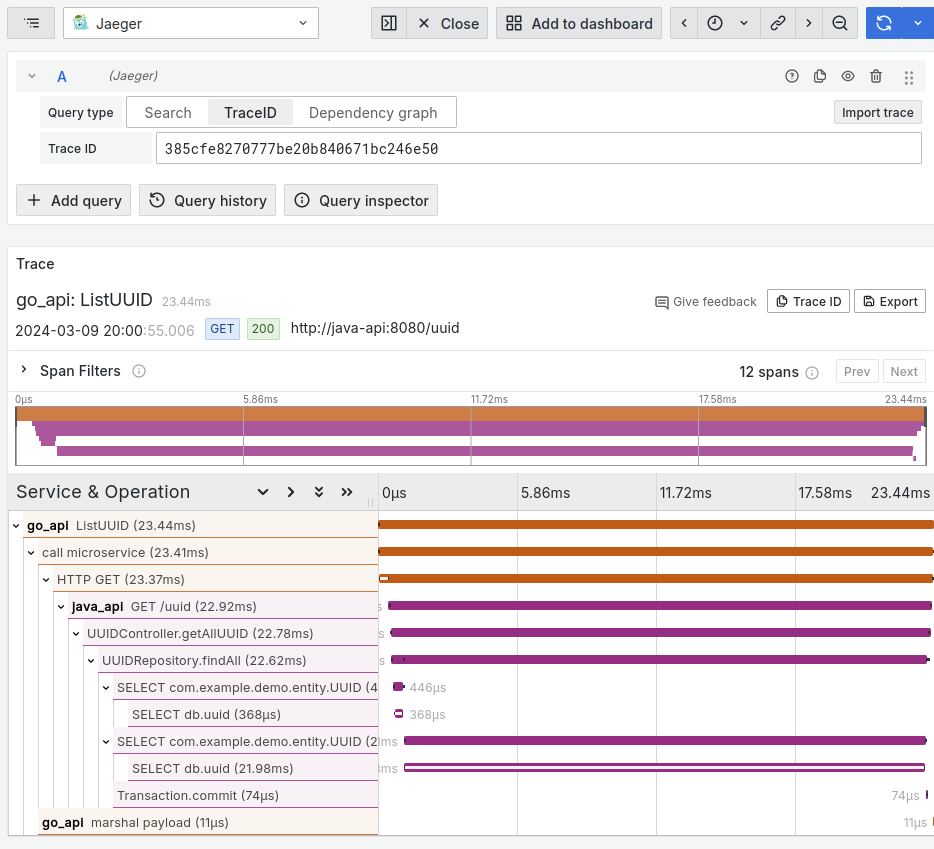 Figure 13: Name and duration of twelve spans for this single trace of this request.
Figure 13: Name and duration of twelve spans for this single trace of this request.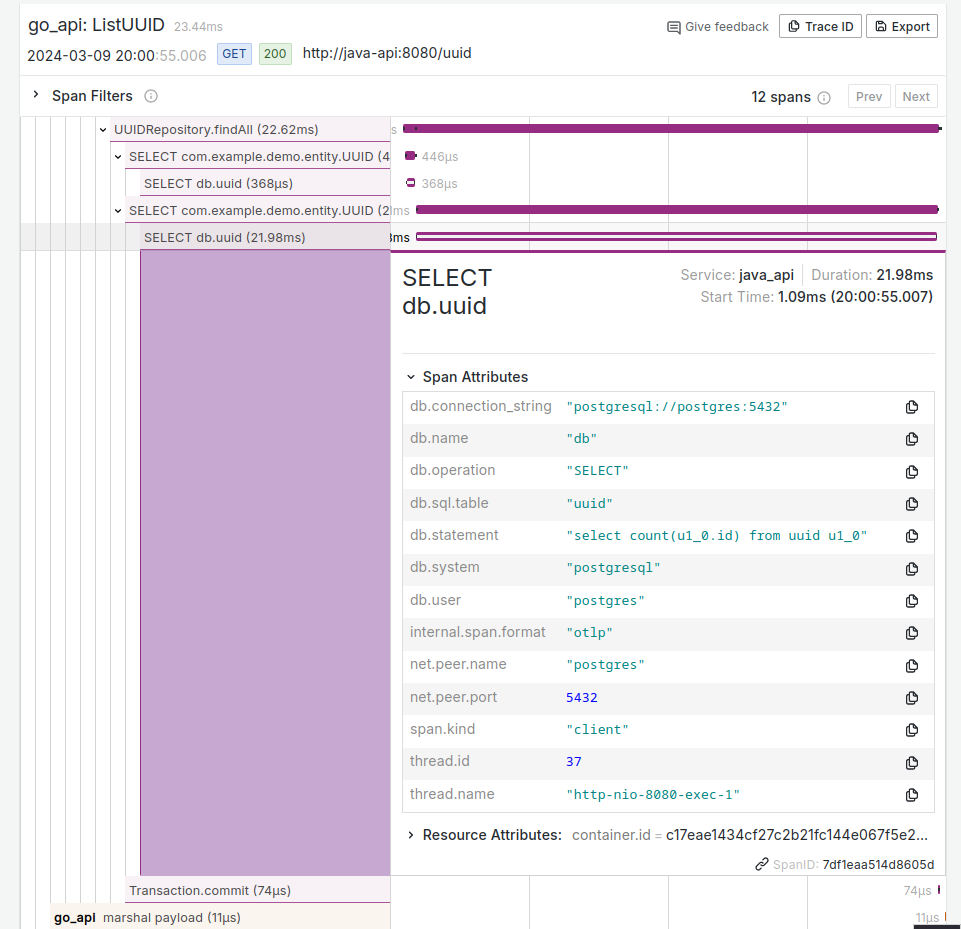 Figure 14: Each span can be clicked to reveal more information.
Figure 14: Each span can be clicked to reveal more information.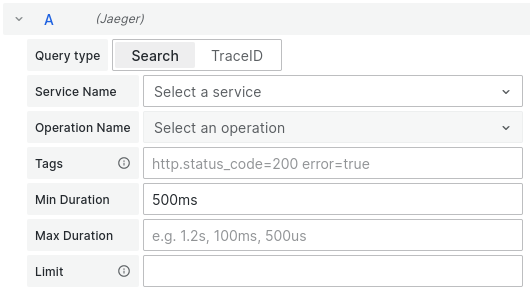 Figure 15: Spans can be filtered to your criteria.
Figure 15: Spans can be filtered to your criteria.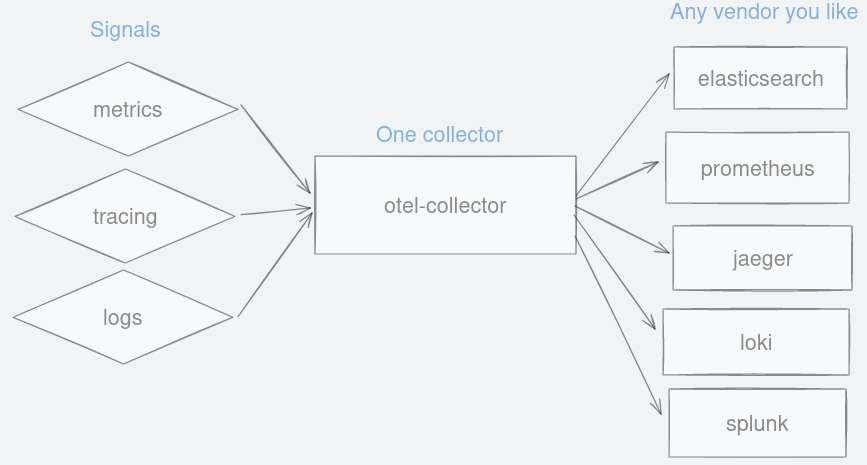 Figure 16: A single collector to forward observability signals to any vendor you like.
Figure 16: A single collector to forward observability signals to any vendor you like. Figure 17: OpenTelemetry belongs to CNCF.
Figure 17: OpenTelemetry belongs to CNCF. Figure 1: Demonstration of the final product
Figure 1: Demonstration of the final product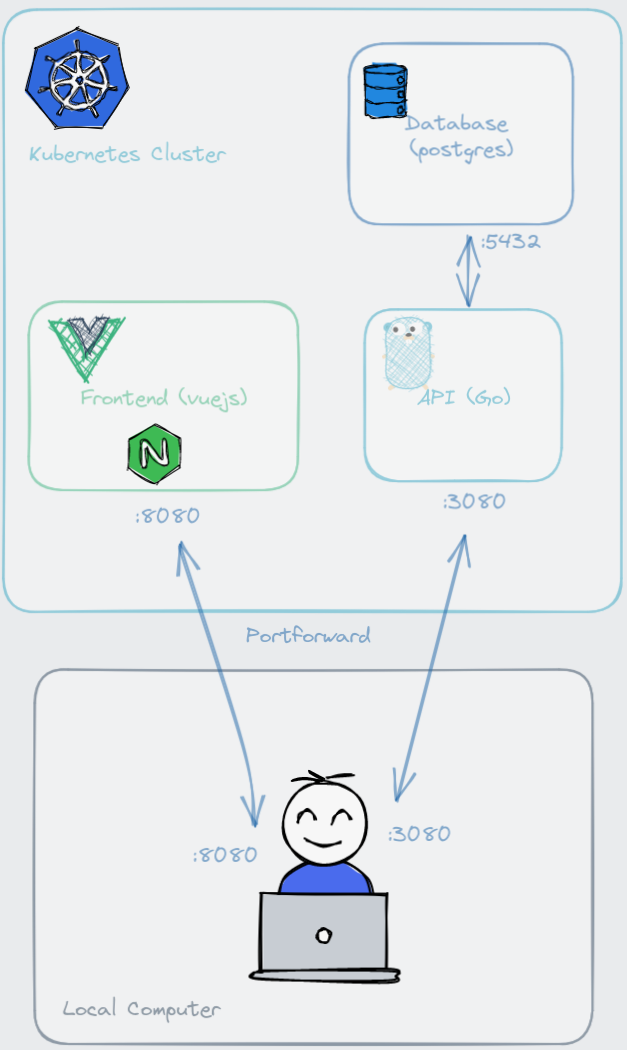 Figure 2: Overall architecture of the applications
Figure 2: Overall architecture of the applications
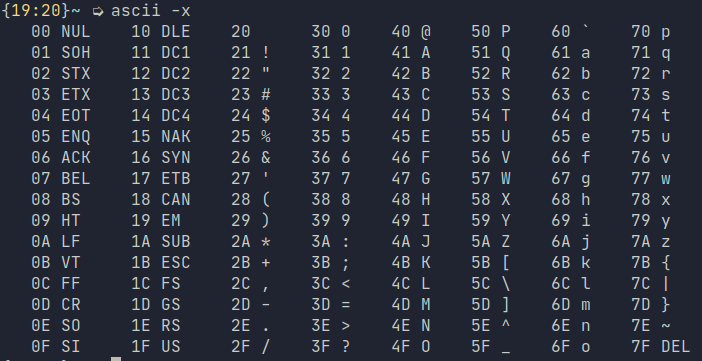
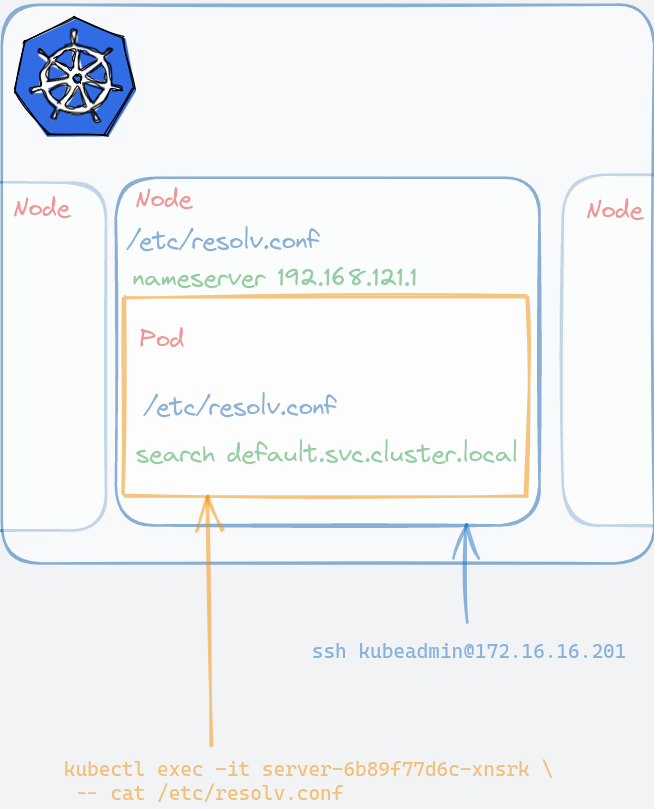
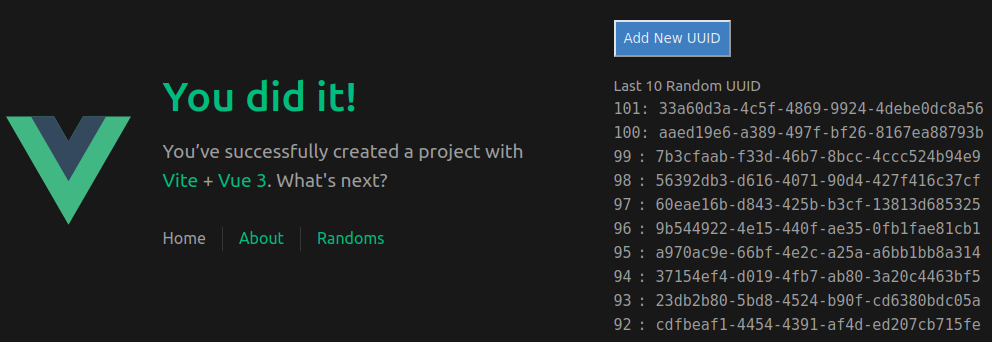

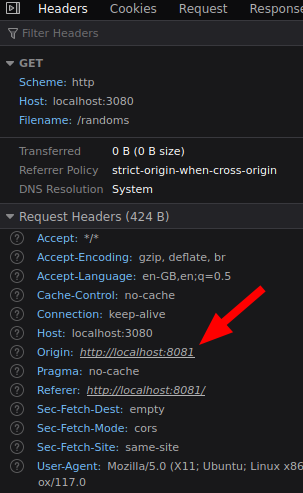
 (from
(from 


 In this post, we will look at listing users with all their addresses. Both
In this post, we will look at listing users with all their addresses. Both 
 In this post, we will look at getting a list of countries along with its addresses.
In this post, we will look at getting a list of countries along with its addresses. From:
From: 

 In this post, we will look at how these libraries and ORM deal with fetching a single record given
an ID. There should not be any drama as we only be doing a simple query as follows:
In this post, we will look at how these libraries and ORM deal with fetching a single record given
an ID. There should not be any drama as we only be doing a simple query as follows: In this post, we will look at comparing listing of user resource. We limit the record to the first
thirty records.
In this post, we will look at comparing listing of user resource. We limit the record to the first
thirty records.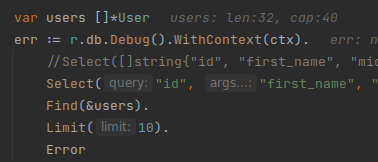 first argument is a
first argument is a 
,_trending_on_artstation,_incredible_vibrant_colors,_dynamic_epic_composition,__ray.png)