Golang Database Library Orm Example - Many to Many
In this post, we will look at listing users with all their addresses. Both users and addresses
tables are joined with a pivot table, user_addresses, which holds the foreign key of each of
users and address table primary key.
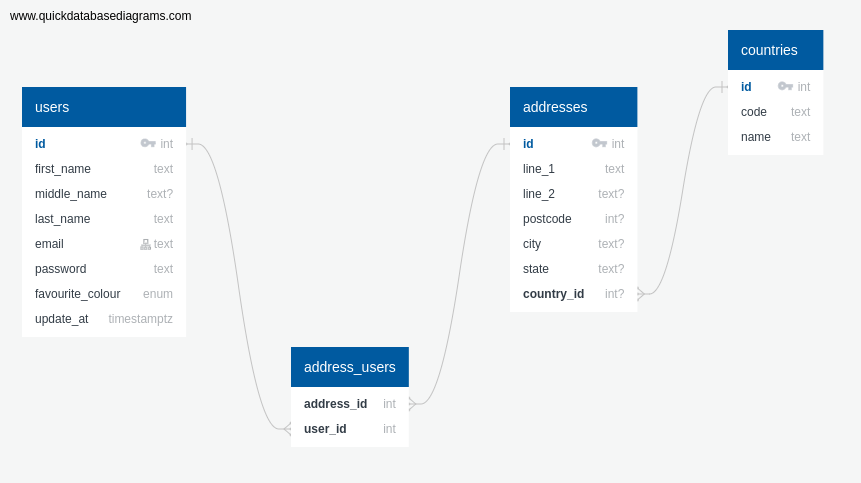
As the erd suggests, a user can have many addresses, and an address can belong to many users.
Table of Contents
This is part of a series of blog posts including:
- Introduction
- Create - Create a single record
- List
- Get - Get a single record
- Update - Update a single field
- Delete - Delete a record
- One-To-Many - Eager load one to many relationship between two tables
- Many-To-Many - Eager load many to many relationships between two tables using a pivot table
- Dynamic List - Return a record with a list of names, sorting, and pagination
- Transaction - Handle transaction, rollback on error
-
SQL Injection - Try to list all users by using malicious query parameters
- and Conclusion
There are many ways to do this. The most straight away method (what most ORM does) is to perform a query on each of the related tables.
- Get 30 records of users
- For each user, get the IDs of the address from the pivot table
- Get all records of addresses from the IDs retrieved in the previous step.
- Begin attaching address to users.
ORMs often do this automatically for you. Writing sql manually means you have to do all the steps above.
The other way is to perform left joins on the tables, starting from users, and ends with addresses.
Left join is important because if we perform an inner or right join instead, if a user do not have
an address, that user record will not be returned. While doing left joins, alias, especially on IDs
must be set to prevent name conflict. In my opinion, this method is a poor fit when doing a
many-to-many operation. The following method is better.
Finally, it is possible to use array_agg (for postgres) function or group_concat for mysql/mariadb.
You write the least amount of Go code but requires you to have a sufficient amount of SQL knowledge
to craft the correct query.
sqlx
We will take a look at two methods, method 1 which by which is by doing a query on each table, and the third method, which is relying on a single query. I will omit the second method because it is much more complicated than method 1.
Method 1: The Long Way
If you look at the full source code, it is 2 pages long. So, I will only include relevant snippets here.
Starting with sql queries, we try to limit number of users to 30.
-- #1
SELECT u.id, u.first_name, u.middle_name, u.last_name, u.email
FROM "users" u
LIMIT 30;
To find out the address of each user, we get that relationship from the pivot table. For an array
of user IDs, we can always do a SELECT DISTINCT u.id FROM users u LIMIT 30;. But this is an
additional query while we can extract the IDs from query #1.
-- #2
SELECT DISTINCT ua.user_id AS user_id, ua.address_id AS address_id
FROM "addresses" a
LEFT JOIN "user_addresses" ua ON a.id = ua.address_id
WHERE ua.user_id IN (?);
We then get all address IDs, pass into the following query, and execute.
-- #3
SELECT a.*
FROM addresses a
WHERE a.id IN (?);
Notice that the two last queries uses ? instead of $1. It relates to sqlx’s ability (or inability)
to properly turn array values for IN operator. So what w can do is to use the In() function to
expand into a slice of arguments.
query, args, err := sqlx.In(UsersAddress, userIDs)
sqlx.In accepts an array of interface but executing QueryContext() expects int8.
Only using ? placeholder sqlx won’t complain about types.
Once we perform the first sql query, we can the result into a custom struct
([]*UserResponseWithAddressesSqlx), one with address field.
type UserResponseWithAddressesSqlx struct {
ID uint `json:"id,omitempty"`
FirstName string `json:"first_name"`
MiddleName string `json:"middle_name,omitempty"`
LastName string `json:"last_name"`
Email string `json:"email"`
Address []AddressForCountry `json:"address"`
}
var all []*UserResponseWithAddressesSqlx
for users.Next() {
var u userDB
if err := users.Scan(&u.ID, &u.FirstName, &u.MiddleName, &u.LastName, &u.Email); err != nil {
return nil, fmt.Errorf("db scanning error")
}
all = append(all, &UserResponseWithAddressesSqlx{
ID: u.ID,
FirstName: u.FirstName,
MiddleName: u.MiddleName.String,
LastName: u.LastName,
Email: u.Email,
})
}
We retrieve all user IDs and get its associated addresses with the second sql query. We need to scan and hold the data with another struct so that wen use it to find the associations later.
type userAddress struct {
UserID int `db:"user_id"`
AddressID int `db:"address_id"`
}
Then get all address IDs and execute the third sql query. Scan the results into a new address struct -
it needs the db struct tag.
The final step is to loop through all array of structs and attach their associations
for _, u := range uas {
for _, user := range all {
if u.UserID == int(user.ID) {
for _, addr := range allAddresses {
if addr.ID == uint(u.AddressID) {
user.Address = append(user.Address, AddressForCountry{
ID: addr.ID,
Line1: addr.Line1,
Line2: addr.Line2.String,
Postcode: addr.Postcode.Int32,
City: addr.City.String,
State: addr.State.String,
})
}
}
}
}
}
Note that if a user record do not have any address, the value for address key will be null,
instead of an empty array.
{
"id": 3,
"first_name": "Jake",
"last_name": "Doe",
"email": "jake@example.com",
"address": null
}
So you need to remember to initialize the addresses for a user
all = append(all, &UserResponseWithAddressesSqlx{
ID: u.ID,
FirstName: u.FirstName,
MiddleName: u.MiddleName.String,
LastName: u.LastName,
Email: u.Email,
Address: []*AddressForCountry{}, // instead of leaving it empty
})
In my opinion, this is too much code for just a simple two tables plus a pivot table to deal with. Imagine having to eager-load 7 tables deep. That is a nightmare.
Method 3: The SQL way
So let us take a look at using the third method, which is using both array_agg and row_to_json
and see if it is anything simpler. If you take a look at the SQL query below, it looks similar to
the query we have done for 1-many, but we are now joining three tables:
SELECT u.id,
u.first_name,
u.middle_name,
u.last_name,
u.email,
u.favourite_colour,
array_to_json(array_agg(row_to_json(a.*))) AS addresses
FROM addresses a
JOIN user_addresses ua ON ua.address_id = a.id
JOIN users u on u.id = ua.user_id
GROUP BY u.id;
The relevant bits are that the JOIN operation starts from the ’lower’ aggregated records
(addresses table) and we work our way up to the users table.
With array_to_json(array_agg(row_to_json(a.*))), we turn each row in addresses as a json
array. After performing the left joins, we select user columns we want and finally group them by
user ids. The result is we only get users that have at least one address.
[
{
"id": 1,
"first_name": "John PATCHED",
"middle_name": "middle",
"last_name": "Does",
"email": "jogn-doe@example.com",
"favourite_colour": "green",
"addresses": [
{
"id": 1,
"line_1": "Sydney Opera House",
"line_2": "Bennelong Point",
"postcode": 2000,
"city": "Sydney",
"state": "NSW",
"country_id": 1
}
]
},
{
"id": 2,
"first_name": "Jane",
"middle_name": null,
"last_name": "Doe",
"email": "jane@example.com",
"favourite_colour": "green",
"addresses": [
{
"id": 2,
"line_1": "Petronas Twin Towers",
"line_2": "",
"postcode": 50088,
"city": "Kuala Lumpur",
"state": "Wilayah Persekutuan",
"country_id": 2
},
{
"id": 1,
"line_1": "Sydney Opera House",
"line_2": "Bennelong Point",
"postcode": 2000,
"city": "Sydney",
"state": "NSW",
"country_id": 1
}
]
}
]
Notice that this SQL query omits users that do not have any addresses. To include them, simply
change the JOIN above to RIGHT JOIN.
One caveat, just like we showed in one-to-many example is that we need to parse the json array from
database back to a Go struct if we want to play around with it. If you don’t we can simply scan into
json.RawMessage.
sqlc
We already know the exact SQL query we need to perform this M2M query so, it is similar to method 3 of sqlx, but with less boilerplate. We do not need to manually scan database results to a struct because they are all generated for you, but you still need to extract IDs from each. For method 1, it only takes a page long to perform many-to-many compared to almost 2 pages long for sqlx.
You still need to manually attach address to a user like sqlx. Also, you need to remember to initialize addresses for a user like above instead of leaving it empty.
Upon sqlc compilation, it generates a method that you can simply use:
dbResponse, err := r.db.ListM2MOneQuery(ctx)
However, since it outputs a struct consisting of sql.Nullstring for middle_name and an enum
for favourite_colour, we want to convert them into another struct
resp := make([]*db.UserResponseWithAddressesSqlxSingleQuery, 0)
for _, dbRow := range dbResponse {
row := &db.UserResponseWithAddressesSqlxSingleQuery{
ID: uint(dbRow.ID),
FirstName: dbRow.FirstName,
MiddleName: dbRow.MiddleName.String,
LastName: dbRow.LastName,
Email: dbRow.Email,
FavouriteColour: string(dbRow.FavouriteColour),
Address: dbRow.Addresses,
}
resp = append(resp, row)
}
squirrel
Like sqlx and sqlc, method 3 is going to have far fewer boilerplate than method 1. The long method 3 is uninteresting because we have already shown how to do it with sqlx. Let us see how this query builder fare.
rows, err := r.db.
Select(
"users.id",
"users.first_name",
"users.middle_name",
"users.last_name",
"users.email",
"users.favourite_colour",
"array_to_json(array_agg(row_to_json(a.*))) AS addresses",
).
From("addresses AS a").
InnerJoin("user_addresses ON user_addresses.address_id = a.id").
InnerJoin("users ON users.id = user_addresses.user_id").
GroupBy("users.id").
QueryContext(ctx)
One look, and you can see that this is almost a one-to-one translation from the SQL query we wanted into Go code. There are a few differences to the approach we made in the 1-to-many section.
First of all, in the 1-to-many section, the whole database response is in JSON format. Here, only
one column is in JSON format, namely the last addresses column.
At first, I wanted to make array_to_json(array_agg(row_to_json(a.*))) AS addresses statement into
its own select using s := r.db.Select("array_to_json(array_agg(row_to_json(a.*)))") and then chain
with FromSelect(s, "addresses") but that did not work.
The inner join argument here is interesting. We pass one string only, unlike other ORM in other languages where they can be separated with commas. Here it can take optional arguments. That means we can do something like this…
InnerJoin("user_addresses ON user_addresses.address_id = a.id AND a.id = ?", 7).
… and it will only return records on the user_addresses join where address ID is equal to 7.
The trickiest part is the scanning, like in one-to-many section, we have to construct a Go struct
specifically for this query. The first six columns for users table are clear. addresses
on the other hand is actually a JSON response - so we need to implement the Scanner interface.
type CustomM2mStruct struct {
Id int `json:"id" db:"id"`
FirstName string `json:"first_name" db:"first_name"`
MiddleName any `json:"middle_name" db:"middle_name"`
LastName string `json:"last_name" db:"last_name"`
Email string `json:"email" db:"email"`
FavouriteColour string `json:"favourite_colour" db:"favourite_colour"`
Addresses json.RawMessage `json:"addresses" db:"addresses"`
}
func (m *CustomM2mStruct) Scan(src interface{}) error {
val := src.([]uint8)
return json.Unmarshal(val, &m)
}
Scanning is just looping and appending.
var items []*CustomM2mStruct
for rows.Next() {
var rowToJson CustomM2mStruct
if err := rows.Scan(
&rowToJson.Id,
&rowToJson.FirstName,
&rowToJson.MiddleName,
&rowToJson.LastName,
&rowToJson.Email,
&rowToJson.FavouriteColour,
&rowToJson.Addresses,
); err != nil {
return nil, err
}
items = append(items, &rowToJson)
}
gorm
Performing many-to-many here is very similar to its one-to-many. We supply a slice to
User pointer and gorm will use reflection to infer what we want.
func (r *repo) ListM2M(ctx context.Context) ([]*User, error) {
var users []*User
err := r.db.WithContext(ctx).
Preload("Addresses").
Find(&users).
Select("*").
Limit(30).
Error
if err != nil {
return nil, fmt.Errorf("error loading countries: %w", err)
}
return users, nil
}
Unlike sqlx and sqlc, a user without address will be marshalled to an empty array
...
{
"id": 3,
"first_name": "Jake",
"middle_name": "",
"last_name": "Doe",
"email": "jake@example.com",
"address": []
}
]
The amount of code needed to be written is also greatly reduced compared to sqlx, sqlc, and squirrel
so far. The key is to use Preload() method. What is not obvious is what magic string you need to
supply to it. The answer is the name of the field itself - it has to match. For example, User
struct has Addresses in its field, so we supply the string Addresses inside Preload().
type User struct {
...
Addresses []Address `json:"address" gorm:"many2many:user_addresses;"`
}
We also need to tell Gorm the pivot table that is used to link between users and addresses table.
It is done by using a struct tag gorm:"many2many:user_addresses;".
Gorm has no code generation like sqlboiler and ent. Instead, it relies on structs (and struct tags) as its point of reference.
sqlboiler
Unfortunately I cannot find an easy way to eager load many-to-many relationships with sqlboiler. Current recommendation is to fall back to raw sql queries.
ent
Like its one-to-many operation, ent shines at loading relationships.
func (r *database) ListM2M(ctx context.Context) ([]*gen.User, error) {
return r.db.User.Query().
Limit(30).
WithAddresses().
All(ctx)
}
We use the same pattern as what we did with one-to-many - {{ With{{Model}} }} pattern.
If a user has no address, the edges key will only contain an empty object.
[
{
"id": 3,
"first_name": "Jake",
"last_name": "Doe",
"email": "jake@example.com",
"edges": {}
},
{
"id": 1,
"first_name": "John",
"last_name": "Doe",
"email": "john@example.com",
"edges": {
"addresses": [
{
"id": 1,
...
Ent makes 3 separate sql queries, just like what we have done for sqlx, and gorm.
In my opinion, the API is very straightforward and there isn’t a way to get it wrong. Everything
is statically typed with no interface{} anywhere which makes it predictable. Only downside I can
think of is you need to spend time getting the relationship in the model schemas correctly.
In conclusion, using raw sql is too much work when it comes to loading many-to-many relationships.
Imagine if we want to load 7 tables deep, it’d be a nightmare. While using sqlc improves upon sqlx
by reducing a good deal of boilerplate, it still pales in comparison to using an ORM. You need to
be careful with struct tag with Gorm, and it was not obvious that you had to use a field name for
Preload(). Ent does not have Gorm’s issues as everything is typed. You will need to learn to using
With... pattern though which isn’t a big deal.