Transactional Outbox Pattern
Prologue
How do you guarantee
- Writing to
mail_deliveriestable; and - Queue a message
…in such a way that they are an atomic operation — both happens or nothing at all.
To see how this problem is difficult to solve, let us consider the following sketch. We have a mail delivery at the fork of two roads and a copy needs to be sent to each of the queue and the database. While sending the messages is easy, what is hard is how can we confirm if the messages reached their destinations. Both queue and database cannot see each other. Sending the message to the database is easy because we can wrap in a transaction. If there are any problems, the transaction will be rolled back.
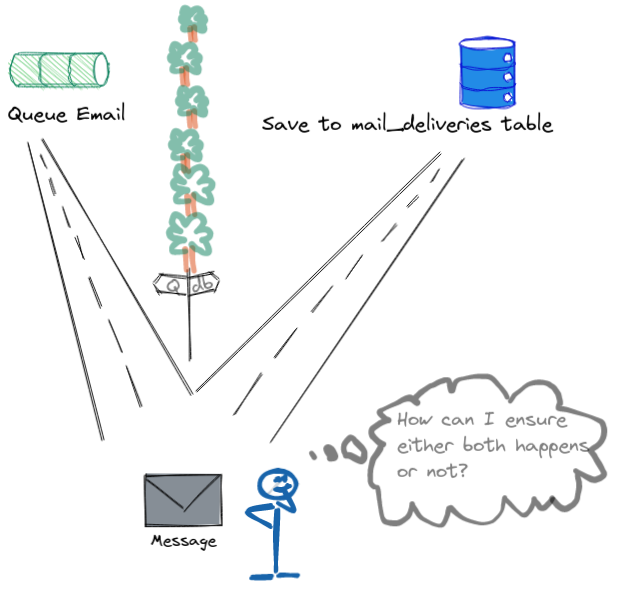 Figure 1: How can the sender guarantee both are delivered
Figure 1: How can the sender guarantee both are delivered
The issue comes with dealing with the queue which can fail. Consider each of the following four scenarios of when we queue the message in relative to saving to the database:
-
Queue message before saving to the database
- But writing to DB may fail, with the task is already queued
-
Queue the message within a transaction to write to
mail_deliveries- Just like above, if transaction fails and rolls back, the task is already queued, and we cannot un-queue
-
Queue the message after saving to the database
- Message is saved to DB, but the queue can fail
-
Queue is successful, but acknowledgement reply has failed
How a queue can fail
- Queue is down/unavailable
- Queue crashes (e.g. out of memory, disk corruption)
- Network failure (e.g. packets drop in-transit)
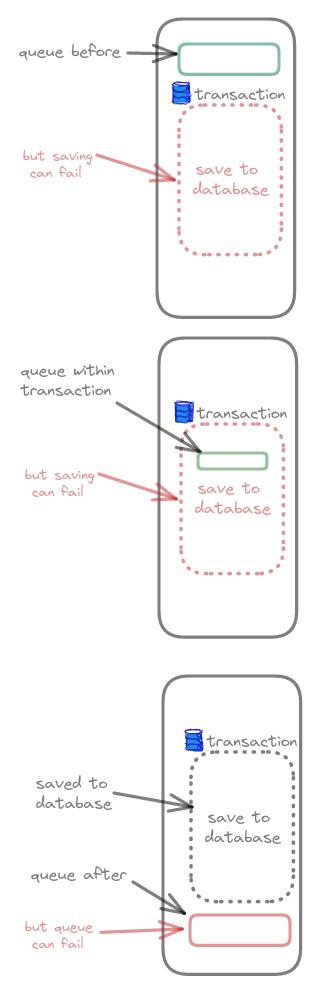 Figure 2: How even with a database transaction is not enough
Figure 2: How even with a database transaction is not enough
Same thing can be said to a database. However, in the event of failing to save to DB, we can rollback a transaction but we cannot do the same with a queue!
Table of Contents
Introduction
In this blog post, we are going to step through this pattern (with some badly drawn pictures!) to see how we can solve this issue. In essence, what we are going to achieve is called an at-least-once message delivery. It means we guarantee that the customer will receive an email.
One solution is to use transactional outbox pattern which is characterised by two things:
- Writing to both
mail_deliveriesandoutboxtables in one transaction - Have a process (which can be called a Producer, Forwarder, or Relay) that
I assure you that this pattern is easy to understand. However, it requires more complexity in the code to implement. You need to ask yourself if it is worth it to implement this pattern. How often do you see your queue goes down? What about your mail service? You may have a highly-available horizontally scalable queue but that doesn’t guarantee it to work all the time. Can you afford to have emails from not being sent to your customers? What is your reconciliation plan? I do not have the answer because it all depends™ on your needs. You might be able to get away with a simple queue right after a database transaction. But if not, read on!
Technologies
To demonstrate this solution, we use four technologies:
- A Postgres database
- Redis for queue
- https://github.com/hibiken/asynq library to manage tasks including queueing and dequeuing as well as pubsub
- A demo service written in Go that sends the messages, and another as a process running in the background
As has been said before, this transactional outbox pattern is independent of any language. The asynq library is a convenience library that also helps with task de-duplication. Any database is fine as long as it support row-locking for SELECT. Although not strictly needed as we will see later, any queue is fine but Redis is chosen for its simplicity.
Bird’s Eye View
To give a birds eye view, the following diagram shows overall process flow in our solution. Only step 1, 2, and 3 are related to transactional outbox pattern. However, this blog post will also cover two important topics. Keen reader will notice that in an at-least-once message delivery mentioned above means that customers can potentially receive identical duplicate messages. To remedy this, we are going to attempt to implement an exactly-once message delivery. We will also touch on the topic of graceful shutdown that ensures everything runs as expected even after a service shutdown and restart to be holistic.
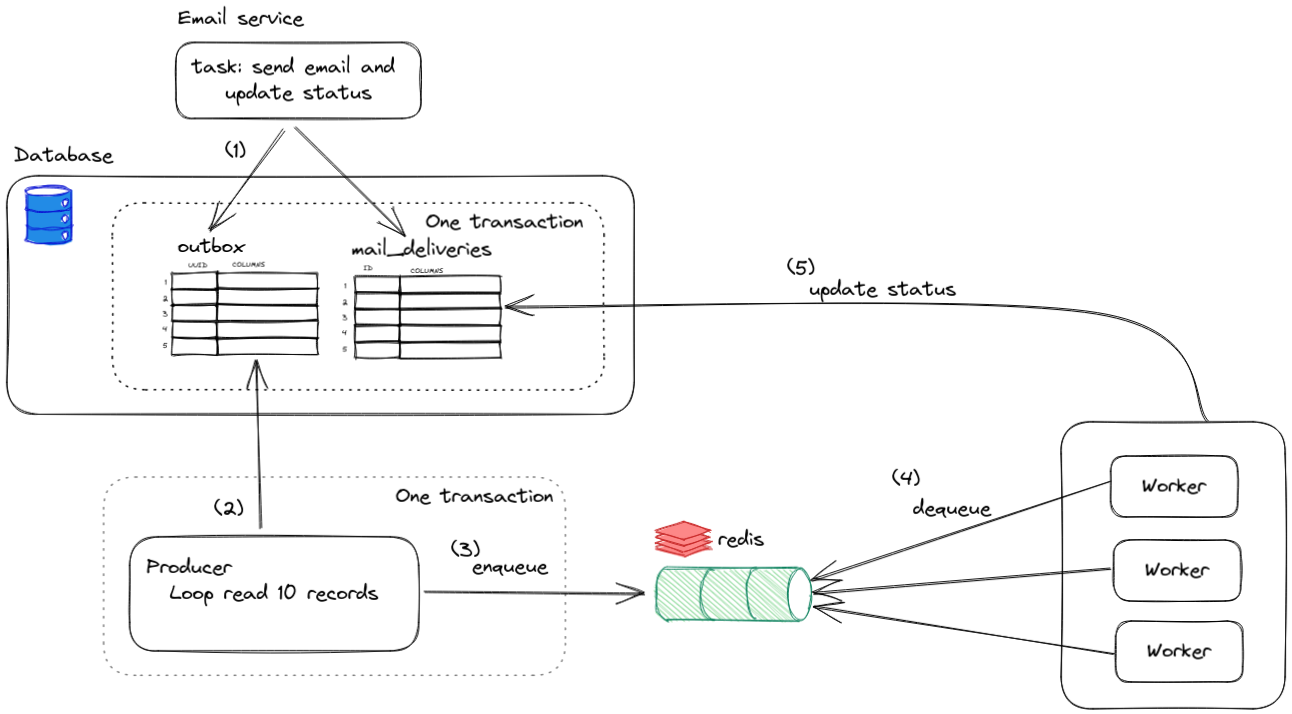 Figure 3: High-level diagram of transactional outbox pattern
Figure 3: High-level diagram of transactional outbox pattern
Let us zoom into each part and go step-by-step in detail.
Step (1)
We are at the fork two roads and, we want to guarantee both status update and email sending to happen. Instead of queuing the mail directly, we write to both mail_deliveries and outbox tables in one database transaction.
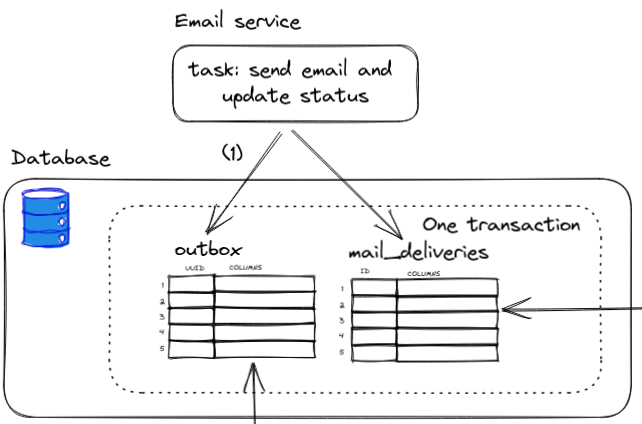 Figure 4: Write to both in one transaction
Figure 4: Write to both in one transaction
If any error occurs, the database transaction will be rolled back and no data are recorded in either table.
There are no rules for the schema of an outbox table but a couple of examples can look like these:
create table outbox
(
id uuid not null primary key,
type text,
payload bytea
);
Code 1: SQL schema that stores both task type and payload
or
create table outbox
(
id uuid not null primary key,
table_id bigint,
table_name text
);
Code 2: SQL schema that only store references of payloads to another table
Either schema will work but the second one is more space-efficient.
Step (2)
For the second step, we have a process we call a Producer that continuously runs in the background in a loop that reads the outbox table to find new records. This process can be called by many names: a Producer, a Relay, or a Forwarder, which all mean the same thing — take one thing and put it somewhere else.
To reduce database load, we can batch read, say ten at a time. Then each of ten records is queued to Redis.
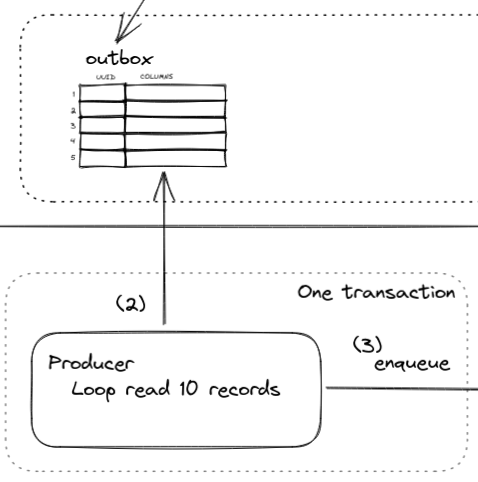 Figure 5: Producer batches loop read outbox table, then queue each one.
Figure 5: Producer batches loop read outbox table, then queue each one.
If there are no records in the outbox table, this producer will just continue into the next loop.
At each loop interval, a maximum of ten records are retrieved from the table to be queued.
What is in the name? An outbox is the opposite of an inbox — similar to an email inbox. The mail you wrote stays in an outbox until it is sent away.
So far it sounded simple. But what problems can arise?
- In a distributed system, there can be multiple Producers reading the same records, thus producing multiple identical tasks to the queue, leading to customers receiving multiple identical emails.
- Like Step (1), queuing can fail.
- We do not want to retrieve rows containing records that have been queued.
For problem 2, it will be covered in the section after the next.
SKIP LOCKED
For problem 1 and 3, in the database, we can lock on the rows until a transaction is committed. This will prevent the same rows from being selected again. Let us look to the database and see what SQL query we can do. Final query is the Code 4 but for now take a look at this:
BEGIN;
SELECT outbox.id
FROM outbox
ORDER BY id
FOR UPDATE SKIP LOCKED -- <- our special SKIP LOCKED
LIMIT 10;
# queue here
COMMIT;
Code 3: Initial SQL query
SKIP LOCKED is the special clause that causes the SELECT to skip already selected rows. As long as this SELECT has not been committed, any other SELECT will not be able to retrieve those claimed ten rows. Basically in outbox, we want the Producer to find the next unclaimed rows. Note that if you are using an ORM, it may not support this clause so, you have to fall back to raw SQL query. Locking reads is supported from postgres 9.5, mariaDB 10.6, mysql 8, oracle, and likely many other databases.
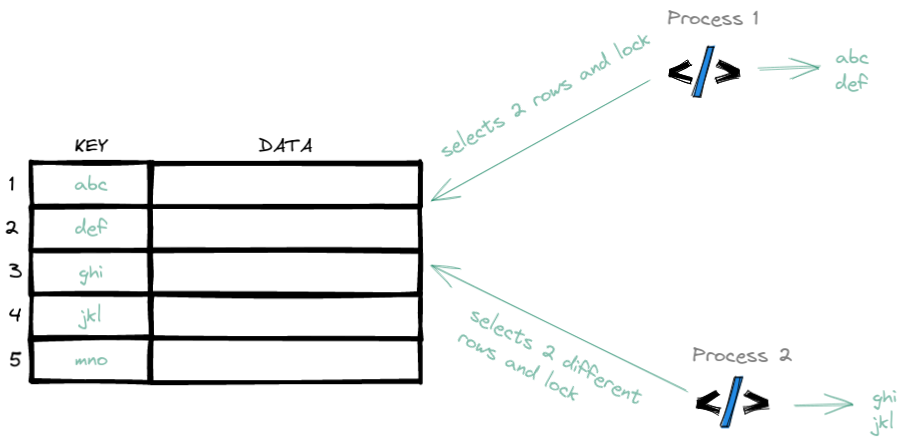 Figure 6: Selecting the same rows by two different processes are prevented using SKIP LOCKED
Figure 6: Selecting the same rows by two different processes are prevented using SKIP LOCKED
In the first SELECT made by Process 1, it selects two records in a transaction. Another process, Process 2, will also try to select two records, but it skips the key abc and def because they both already have been selected by Process 1 and the transaction has not been completed.
Once the transaction on outbox records is committed, the lock will be released and other Producer (or Process), will be able to select those processed outbox records. This situation is not desirable because we do not want to queue the same thing many times. So we need a way to prevent this. There are two approaches:
- In the outbox table, have a column called
completed_atand fill with current time once that record is queued. So when we do aSELECT, we also check forWHERE completed_at IS NULL;; or - Once that record is queued, just delete from the
outboxtable.
Using the second approach, let us modify our previous SQL query:
BEGIN;
DELETE FROM outbox -- delete after we are done
WHERE id IN (SELECT o.id
FROM outbox o
ORDER BY id
FOR UPDATE SKIP LOCKED -- <- our special SKIP LOCKED
LIMIT 10)
RETURNING *;
–- queue here
COMMIT;
Code 2: Final SQL query
Here, the selected 10 records are queued to Redis one by one. No other SELECT is able to select those 10 records because they are row-locked. Once the transaction is committed, it will delete all 10 records. So again, nothing else can access those 10 records anymore.
Both problem 1 and 3 are solved. For problem 2, we need to solve a situation when a queue fails.
Basically in outbox, we want the Producer to find the next unclaimed rows
When Queue Fails
In the 10 queues, it can fail for many reasons and to maintain atomicity, we roll back the transaction so that we can retry all the queues. At this point, the row locks on the 10 records will be lifted, potentially leaving a mixture of records already sent to the queue and some which do not. After the row locks are lifted, another (or the same) Producer can re-select the same or some of the records that have been queued. This is one scenario of the system trying to queue the same record twice.
If the task has been queued, they are okay. But two scenarios can happen:
-> Queued tasks: We will see in more detail in Step (3) but the queue will return an error such as:
- the task is currently running; or
- the task has already been processed which the queue identified by looking at each record’s unique ID; or
- the task did came through and accepted by the queue but the acknowledgement to the email service is lost, and you get a timeout error. Lost acknowledgement has been studied in detail in the literature, see Two General’s Problem.
-> Non-queued tasks: This particular task will be its second attempt to be queued. If the queue is successful, then good. Otherwise, the loop is repeated.
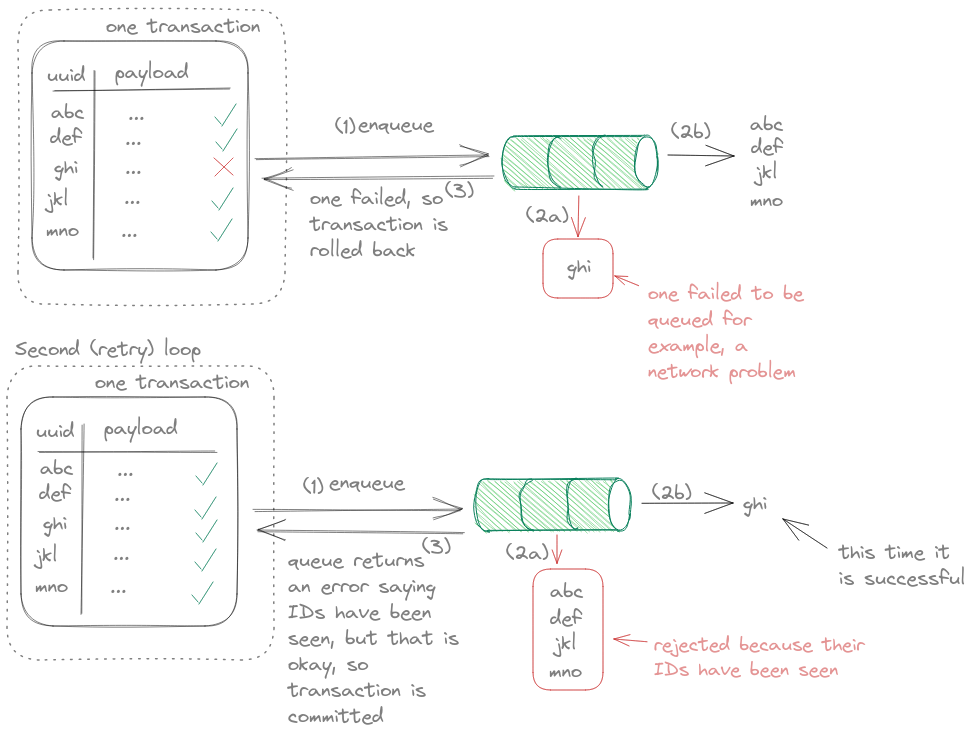 Figure 7: How a failed queue is retried when a transaction is rolled back. Also pay attention to uuid column type.
Figure 7: How a failed queue is retried when a transaction is rolled back. Also pay attention to uuid column type.
When all tasks are queued with no other relevant errors, the transaction is committed and those records are removed from the outbox table thanks to doing a DELETE FROM outbox …
Because of the queue acting as a sieve, this is all possible. It identifies which tasks have been processed and which do not.
Step (3)
Why Queue At All?
Before explaining the third step in detail, let us take a step back and see why we queue at all. Consider the following scenario. Let’s say that we have saved
a record into the mail_deliveries table, and then we decide that we want to make a synchronous SMTP
request to send an email. In each request, we get an acknowledgement (ack) of a successful request.
If we get both (database and SMTP) ack, we know that both operations are successful. It sounded simple but there are drawbacks to this approach. Firstly, we are assuming both database and mail server to be running 100% of the time, and at the same time. This is called temporal coupling (greek: tempo = time), and this is a typical issue in such tightly coupled services. Secondly, sending an SMTP request can take a while for example you may be rate limited by the mail service of your choice. Lastly, and most importantly, we do not want to make our client to wait for all mails to be sent because it can take several minutes especially when you have a lot of mails to be sent.
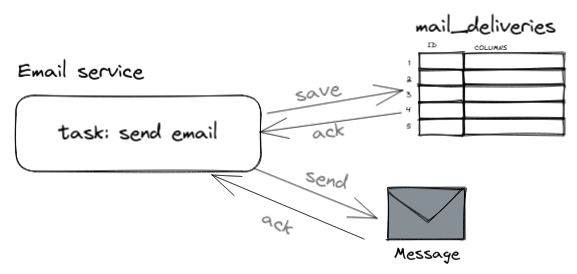 Figure 8: Synchronous requests
Figure 8: Synchronous requests
To solve this, we can loosely-couple our service against mail delivery by using a queue. Now, it does not matter if your mail service is down — the task will be held in your queue until mail service is up. The same story goes if you are rate limited by the mail service. I hope I’ve convinced you why we use a queue.
Exactly-once delivery
So far the system guarantees an at-least-once message delivery. This is achieved by having the state stored in the outbox table and is ensured that they are transported to the queue by some process. The records in the outbox table are selected and row-locked to ensure no rows are selected twice. Once the transaction is committed, those records are deleted from the table.
Now, we focus on how we achieve exactly-once message delivery.
As mentioned before, delivering identical messages more than once is possible because among the batch of ten records, one or more may fail to be queued. This rolls back the transaction for all ten records even though some may have gone through the queue. The next loop could pick up those queued records causing them to be sent to the queue again.
So how do we prevent this? To solve this, we use a concept from mathematics called idempotency. It simply means no matter how many times you run an operation, the result will stay the same as before. In maths language:
f(x) = f(f(x))
where
f = an idempotent function
x = a parameter
Equation 1: Idempotency formula
It may sound unintuitive because let us take this example. In a normal world, if you have 1 apple, and you add 2 apples, you’d get 3 apples, not 2.
 Figure 9: 1 + 2 = 3 right?
Figure 9: 1 + 2 = 3 right?
But in reality, messages are unique. So let us try different kinds of delicious fruits. Let us say you ate one durian and one mangosteen:
 Figure 10: We want idempotency
Figure 10: We want idempotency
As a result, you ate two fruits, correct? However, your doctor saw you ate the mangosteen and said that you should cut down on sugary fruits. Durian is ok, its glycemic index is lower 😋.
You are then offered another mangosteen. What do you do?
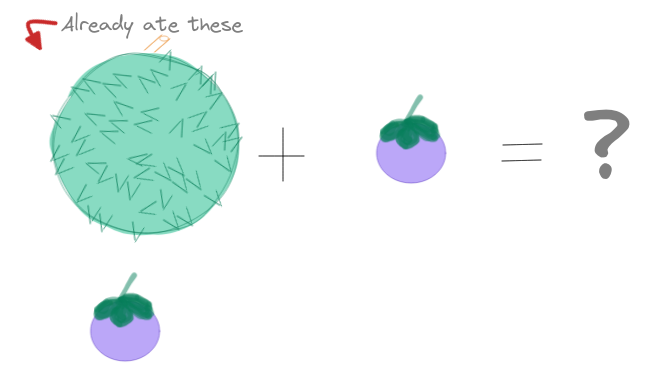 Figure 11: Idempotency rule
Figure 11: Idempotency rule
Obediently, you refuse a second mangosteen and as a result, you still only ate two fruits (for the day 🤣).
The same thing can be done in a queue system. We want to reject identical messages from being queued. For the system to be able to identify, we must attach unique IDs to each record. This way, the queue (the doctor) can identify the record(mangosteen) is the same.
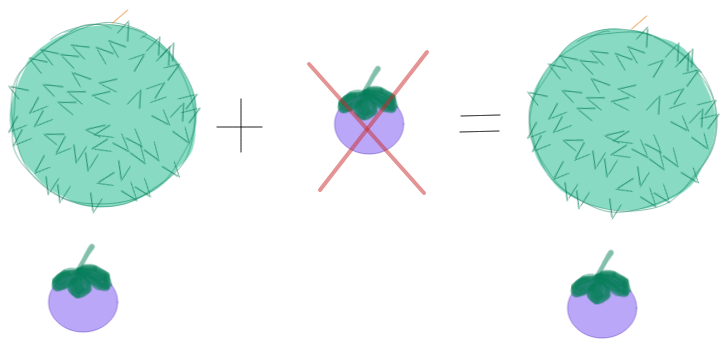 Figure 12: Second mangosteen is rejected :(
Figure 12: Second mangosteen is rejected :(
If we look back to Figure 4, notice that each record has a unique UUID primary key and is inserted within the same transaction as the mail_deliveries table. A queue (look in Figure 7) uses that unique key to determine whether to accept this message into the queue for a consumer to work on it or to reject.
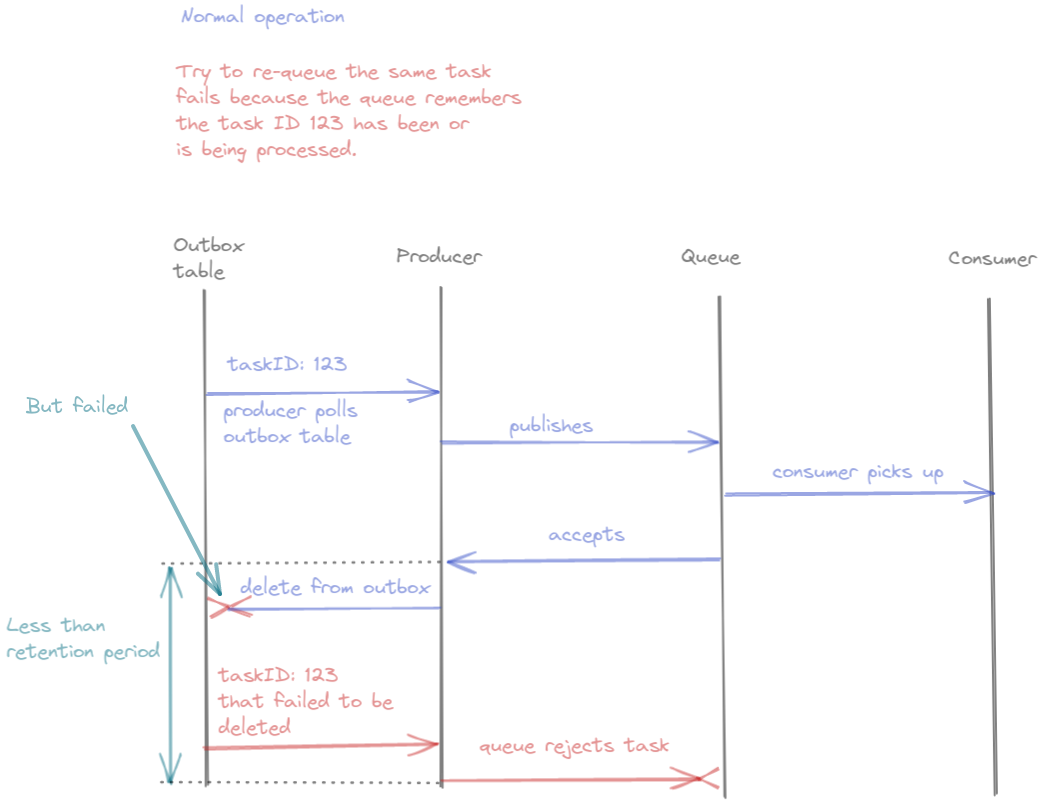 Figure 13: Timeline of sending the same message to the queue
Figure 13: Timeline of sending the same message to the queue
In the timeline above, the blue timeline shows normal operation. Sending the same message, identified by its unique ID however, will be rejected by the queue. In the library, there is a choice of both manually assigning the task a unique ID and a retention time. The retention time tells the library to hold already processed IDs in the memory for a period of time to ensure that if an identical task comes through, it will be rejected. Concretely, we can do like the following:
t := asynq.NewTask(msg.Type, msg.Payload,
// To make each message idempotent, we assign our created unique ID to the queue.
asynq.TaskID(msg.ID.String()),
// Holds that ID for a period of time for asynq to check for uniqueness.
// If the second identical message is pushed to asynq after the retention period is over,
// we will get duplication of message. The longer retention, less chance of duplication,
// but at the cost of using more memory holding the IDs.
asynq.Retention(24*time.Hour),
)
Code 3: Using asynq to create a task
Step (4)
As mentioned early in the post, both step 4 and 5 are not strictly part of a transactional outbox pattern. But for completion’s sake, it is useful to show what we can do here after tasks are queued.
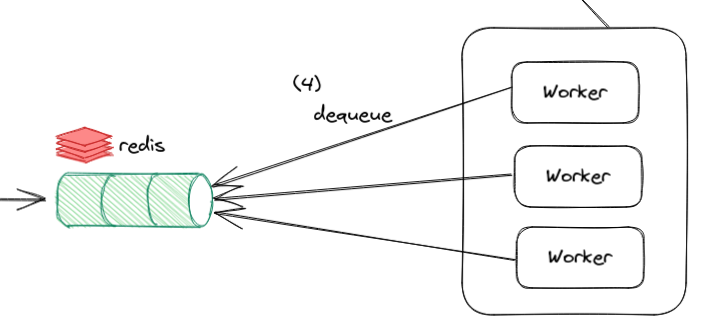 Figure 14: Pop (dequeue) a task from the queue to be processed
Figure 14: Pop (dequeue) a task from the queue to be processed
In a distributed architecture, we want multiple workers that can pop a task from the queue. You may wonder if different worker processes can pop the same task causing duplication of work. Fortunately, this is not an issue because in Redis, we can atomically return and remove (which is a pop) an element from a queue.
Another concern is what happens when a task is popped from Redis and removed entirely (using BRPOP command) for a Worker to work on it, and then for any reason, the Worker crashes or killed. In this scenario, the task is lost forever and there is no way to recover that lost task. This Asynq library uses the RPOPLPUSH command which maintains two list instead for higher durability. More details are described when discussing Sidekiq OSS and Pro in https://www.bigbinary.com/blog/increase-reliability-of-background-job-processing-using-super_fetch-of-sidekiq-pro.
Step (5)
What I like to do is to update a task’s status. Once a task is popped, we update the database saying that we are processing this task. And once it is completed, we update its status to completed.
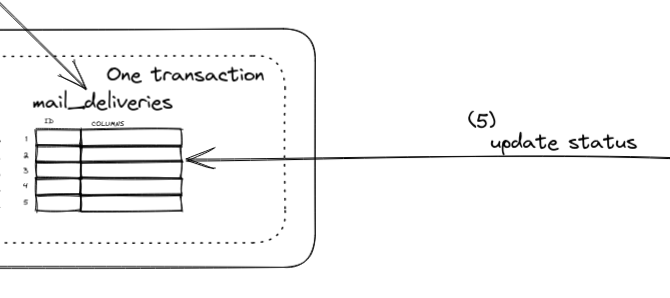 Figure 16: Try to update status
Figure 16: Try to update status
But consider this. We are doing both database update, and sending an email from these workers. It sounds like we are doing the same thing as in the beginning which means we are facing the same issue of guaranteeing two things to happen!
By simply wanting to update a status, at this point, we have lost the exactly-once delivery and we are back to at-least-once delivery. At any of the following four steps can an error happen.
func (w *Worker) ProcessTask(ctx context.Context, task *asynq.Task) error {
// 1. receive payload
// 2. update DB processing on this task has started
// 3. send email through SMTP
// 4. update DB saying this task is complete
}
Code 4: An example of a flow processing a task in the worker
Fortunately, the library will retry for a number of times thanks
to checking this method’s error return value. To tell the library that the task is completed, we simply return no error. If SMTP request has failed, we return that error and the library will retry. If SMTP request is successful and the following database operations are also successful, we finally re-acquire exactly-once delivery. This is an example of eventual consistency.
In a situation when an SMTP request is successful but the following database operations failed, we return no error to tell asynq to mark that the task is completed even though the task’s database record is left in an inconsistent state. In this situation, there are a number of things we can try:
- For any
mail_deliveries.statusrecord that has failed, must reconcile with mail provider; or - Have a background process (just like Producer) that re-attempts to queue
mail_deliveriesrecords with failed status. If the queue rejects because that task has already been processed, attempt to update status from failed to complete status.; or - Use Postgres’
LISTEN/NOTIFYthat triggers an api to re-attempts to queuemail_deliveriesrecords with failed status. Just like (2) but we save on database resource from polling every second.
As you can see, we must keep this gotcha in mind when doing anything that can fail after the SMTP request.
Extra
To be holistic, we will touch on the topic of graceful shutdown. But before that, we go off on two tangents.
Database as a Queue
Now that you understand that Producers select tasks from database to be sent to the queue, and workers pick off those task from a queue, you might think why not those workers select tasks from the database? This skips using and Producer and queue, thus simplifying the whole architecture. This strategy is actually legitimate. The workers will just do the same thing Producer has done. By using the SKIP LOCKED query that we have seen above, the database works as a queue!
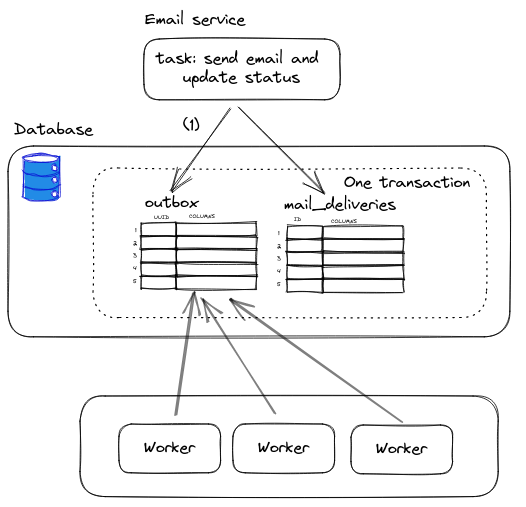 Figure 15: Using database as a queue and letting workers to select tasks
Figure 15: Using database as a queue and letting workers to select tasks
There are two important points to remember when doing this approach:
- For the duration of the transaction, database connection will be held throughout task processing.
- The number of tasks you can process depends on how many database connection pooling you can maintain
For the first point, since no other system is using the row other than the one worker, this is fine. We would not have other transactions waiting until the lock is lifted. However, that limits the number of available connection pool for other tasks to run. This brings to the next point.
For the second point, if you have many concurrent tasks to be processed (high load and long-running tasks), you will have to scale the number database connection pooling, and this can be hard and consume a lot of memory.
Of course other than these, using a dedicated queue system like Redis allows task pausing, retry, priority queue and many other extra nice features.
That said, a database on a small desktop CPU without tuning can easily handle hundreds of tasks per second (at 100/second, that is about 10 million tasks per day!) and if many tasks are short-lived and you don’t need extra features, starting with the database as the queue system is certainly a valid approach. It is rarely a mistake to start with Postgres then switch out the most performance critical parts when the time comes.
Change Data Capture (CDC)
As a second tangent, while using database as a queue simplifies your infrastructure, you may also consider using a change data capture (CDC) solution to offload work from your database. In a database system, any changes are written to a write-ahead log before it is actually written to the database. A CDC like Debezium can be utilised by continuously monitoring this log to find new additions to the outbox table. Then you can ‘sink’ it to a destination like Kafka or Redis. You want to keep this table small so processed records should be removed. if SKIP LOCKED SQL clause is not available, CDC is certainly a valid choice.
Graceful Shutdown
12 factor app says that a service must be disposable. It means a service is not only needed to be quick to start, but able to refuse more work while it is shutting down without dropping current task.
Ability to refuse work is important because we do not want a task to be gone and irrecoverable when a worker dies whenever we publish new code to production. Since we have two services which are Producer and Worker, we will look at each if them
Producer
We simply listen for some operating system signal such as terminate and interrupt which are SIGTERM and SIGINT respectively. These signals can be captured by the Go program and then the process of shutting down can begin. The first thing we do is to stop receiving http requests. After this is done, we begin to shut down connection to the database, redis and any other resources. It may be a good idea to have a timer make a hard stop.
Consumer
Gracefully shut down of consumer is much more important because this is the part where we can potentially lose a task forever. Imagine a worker pops a task from the queue, starts processing, and then told to stop before finishing. We need to give the Worker time to handle this. In short, we:
- Give a moment as a grace period for current tasks to complete
- If a task is not completed yet after grace period, re-queue
Drawbacks Or Footguns
This technique is not without any drawbacks.
-
If you want to perform a database operation in the worker, keep in mind where it can fail because we can potentially lose exactly-once-delivery and requires reconciliation.
-
Processing or processed task IDs are stored in the memory for task de-duplicating purpose. A short ID retention time may cause task duplication if the second task came later. A longer retention time reduces this risk at the cost of using more memory.
-
Related to previous point, since tasks are queued in a queue messaging system, keep in mind how much memory are available and how many connected clients it can handle for concurrent task processing.
Conclusion
As you can see, the outbox pattern is although elaborate, only consists of two main ideas:
- Writing to an
outboxtable. - A Producer reads the
outboxtable to be sent to a queue.
Writing to an outbox table along with another in a transaction is key. A long-running process then picks up tasks from the outbox to be queued. SKIP LOCKED sql clause ensures that we only pick up a record once. Workers then pop a task from the queue to be processed.
Depending on your use case, you may get away without this outbox pattern and hope your queue always work. Or perhaps your scale is small and using the database as a queue is sufficient. However, this pattern gives a high degree of confidence of your system work correctly.
Reference
-
https://microservices.io/patterns/data/transactional-outbox.html
-
https://medium.com/@mokiat/proper-http-shutdown-in-go-bd3bfaade0f2
-
https://gokhansengun.com/why-do-long-db-transactions-affect-performance/
-
https://threedots.tech/post/when-sql-database-makes-great-pub-sub/
Further Reads
-
Consistency, Availability, Partitioning — pick only two! https://en.wikipedia.org/wiki/CAP_theorem
-
Mangosteen 😋 https://www.sydneymarkets.com.au/recipes-and-produce/blog/articles/2017/01/13/exotically-different-mangosteens/