UUID For Database Primary Key
May 1, 2023Why, and when do you use a universally unique identifier (UUID) as a primary key in a database?
- Can create records concurrently because it does not have to wait for the next ID like in sequential ID. So multiple machines can generate them independently which means potentially faster write.
- Scaling is easier. We generally do not have to worry about ID clashing between databases held in different servers.
- Leak fewer information on HTTP response or URL compared to integer primary key.
What are UUID?
They are 32 hexadecimal characters consisting of 16 octets, thus 16*8 = 128 bits. It has an 8-4-4-4-12 format length separated by dashes where each section corresponds to a specific way of encoding.
They look something like this
c50ab83b-b632-419d-91b9-626895e705ec
Figure 1: An example of a UUID
Version of UUIDs
There are many versions ranging from V1 to V5. V4 is what almost everyone uses. It is native to postgres and mysql. It has 6 bits predetermined that contains a version (V4) and a variant. That leaves 122 bits for other random bits for a total of 2122 possibilities.
V1 and V2 include hardware MAC for easier scaling between nodes in a sharded database. So, there’s no collision of primary keys between the shards. These include timestamps of 100 nanosecond precision in the leading portion of UUID, so they are k-sortable. More details on what k-sortable is in the later section.
V3 and V5 are namespace-based with different hash, MD5 and SHA1 respectively.
Collision
Collision happens when generated results have an identical value. This is a significant issue when used as a primary key which requires uniqueness. Generally, collisions have a low chance of happening. To find out, we use the Birthday Paradox formula. We know V4 has 122 bits left for random part, thus:
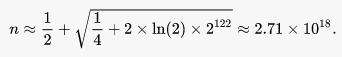 Figure 2: Birthday Paradox calculation https://en.wikipedia.org/wiki/Universally_unique_identifier#Collisions
Figure 2: Birthday Paradox calculation https://en.wikipedia.org/wiki/Universally_unique_identifier#Collisions
“This number is equivalent to generating 1 billion UUIDs per second for about 85 years. A file containing this many UUIDs, at 16 bytes per UUID, would be about 45 exabytes.” https://en.wikipedia.org/wiki/Universally_unique_identifier#Collisions
One in 2.71 * 1018 is an incomprehensible small number. To visualise this, the chance of getting two identical UUID is less than a combination of getting hit by an asteroid (1 in 1,600,000 https://www.nationalgeographic.com/science/article/160209-meteorite-death-india-probability-odds ), and hit by a tsunami (1 in 5000 years https://www.abc.net.au/news/2018-10-16/what-would-happen-if-a-tsunami-hit-sydney/10376680 ) (1-12 ) every single day for a year.
Locality
The reason against using UUID instead of serial ID is that is bad for indexex. Serial integer has no issue with indexes because the way they are indexed in a database are next to each other.
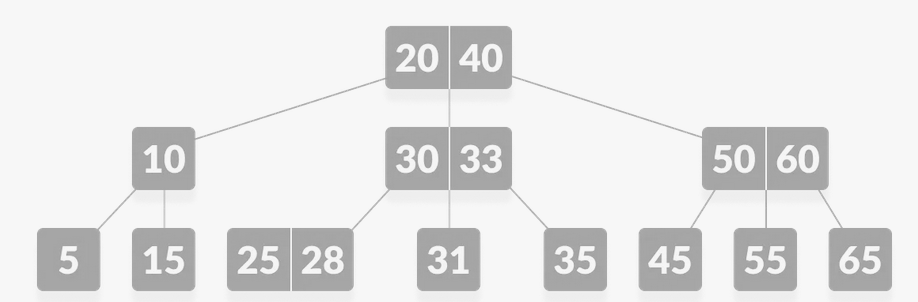 Figure 3: Where the numbers are stored in a tree https://www.programiz.com/dsa/b-tree
Figure 3: Where the numbers are stored in a tree https://www.programiz.com/dsa/b-tree
Here we can see that the integers in the leaf nodes are close to each other.
If a random UUID like V4 is used, a sequence of them will be all over the place, making lookup longer. For example, take a look at the following sequence eight UUID V4 where the top comes first and the bottom is the last item in a table.
4ab20c83-d608-479b-9e3a-9a4d3c68b814
62135145-2ccd-4796-a43a-0d8d4e985e20
6e2b46f6-1f13-46da-8405-9e098c46682c
1a42dd94-6f8c-4d37-a5d9-5f35d3cb8646
5fa03e57-060a-464f-bd98-cec94dad3cf0
2c24a9a5-7638-41fb-814b-5a8ad91e6a69
89d1cde2-52f0-4e9a-87c1-c2ce0ed22c60
948bbc46-92b1-4611-a46b-41055bfdf249
When we index using b-tree, it will look like this
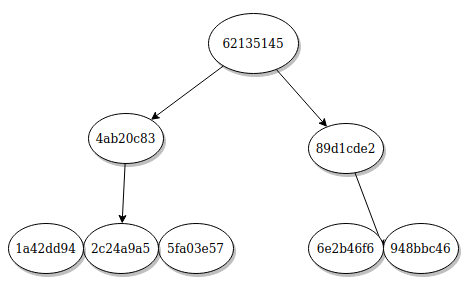 Figure 4: An Example of UUID V4 b-tree index
Figure 4: An Example of UUID V4 b-tree index
The items above only use the first eight characters because only the first few characters are important to demonstrate locality. As you can see, going from the first to the second UUID (4ab20c83 to 62135145) is relatively close, but going to the third one which is 6e2b46f6 is relatively further away. It keeps jumping between nodes which means more pages (memory) and cpu cycles needed to find the nest item. In other words, new items are far away from each other.
UUID new drafts
To combat this locality issue, there are new UUID draft that include version V6, V7, and V8. Both V6 and V7 include timestamps just like V1 and V2, but with an option of a nanosecond precision instead of 100ms precision. The rest are pretty much random numbers. As a result, these UUIDs are k-sortable because they are located near each other, providing near-optimum for a b-tree index.
Anatomy of UUID V7
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unix_ts_ms |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unix_ts_ms | ver | rand_a |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|var| rand_b |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| rand_b |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Figure 5: Anatomy of draft UUID V7 https://www.ietf.org/archive/id/draft-peabody-dispatch-new-uuid-format-04.html#name-uuid-version-7
- 48 bit unsigned number of Unix epoch timestamp
- 4 bit UUID V7 version
- 12 bits pseudo random to provide uniqueness
- 2 bit reserved for variant
- Final 62 bits for uniqueness totalling(So 1.62*1011 possibilities)
Examples of UUID V7 look like this:
# a sequence of 10 UUID V7 with nanosecond precision
061e25e4-1006-74fe-8081-00da525240d0
061e25e4-1006-74fe-ba51-0003f230c720
061e25e4-1006-74ff-8e5b-000923405452
061e25e4-1006-74ff-985b-00c1ce4ad579
061e25e4-1006-74ff-a201-004757a8a95d
061e25e4-1006-74ff-ab75-0078d72c6d62
061e25e4-1006-74ff-b54d-00a551e8bf84
061e25e4-1006-74ff-bed5-00bd7cbafc48
061e25e4-1006-7500-888f-001ea722617d
061e25e4-1006-7500-920d-00a5a9687d6a
Broken down (4 bit is 1 character):
061e25e4-1006 : We can see the first 12 characters are the timestamp. All are created in the same nanosecond
7 : 4 bits for version are all 7 for version.
4fe : 3 random characters
8081-00da525240d0: 2 bits for variant and the rest are 62 bits of random characters
UUID V7 vs Serial ID
In terms of the difference between UUID V7 and a serial ID, one major advantage of UUID V7 is that generation is independent of nodes or shards. However, it leaks timestamps so an attacker can extract a record’s creation date.
Nevertheless, it leaks no other stuff found in serial ID such as:
- Size: If a client receives a record with id=10004578, they can guess that 4578 orders have been made.
- Rate of growth: Receiving two different orders means they can track the growth rate of record insertion.
- Iteration attack: If your API endpoints do not have authorization, an attacker can try to access with
GET /api/users/1,GET /api/users/2,GET /api/users/3, etc. UUID makes this next to impossible.
As we will see later in benchmark section, querying makes no difference. Insertion will be longer because we needed to create the UUIDs client-side — albeit done concurrently.
Difference between UUID V7 and Serial ID
The table below summarises the difference between the two.
| UUID V7 (Draft) | Serial ID | |
|---|---|---|
| Status | Draft | n/a |
| Generate | No need of internal function to calculate next ID but client-side generation can take longer | Internal function to calculate next ID |
| Insertion Time | Longer because it has to be indexed. But should not be a bottleneck | Fast |
| Package | Not native to mysql/postgres. Extra time to create | MySQL: BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY; Postgres: BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY; |
| No Collision | False. But pretty much non-existent | True* |
| Sortable | Yes, k-sortable | Yes |
| Random | Yes | No |
| Timestamp Precision | Up to nanosecond | n/a |
| Btree Index | Good | Excellent |
| Shard between nodes | Yes | Have to coordinate between nodes so IDs do not clash |
| Safe for replication | MySql: No. Might only be applicable to UUIDv4 | Have to take care of duplicate IDs between nodes |
| Potential expose information to client | Yes, because timestamp is viewable | Yes. Size, rate of growth, iteration API call attack: user ID = 1, 2, 3, …) |
Table 1: Comparison between UUID V7 and Serial ID
* In postgres, if you use bigserial unsigned (serial) instead of bigint generated always as identity (identity), there can be a case when ID clashes - https://www.cybertec-postgresql.com/en/uuid-serial-or-identity-columns-for-postgresql-auto-generated-primary-keys/
Benchmark
A quick unscientific benchmark shows there are not much difference between using UUID V7 and serial ID
Simple schemas were used:
CREATE TABLE serial (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
counter bigint
);
CREATE TABLE uuid (
id uuid PRIMARY KEY,
counter bigint
);
Code 1: Schema for both UUID and serial ID
UUID V7 was generated using https://github.com/gofrs/uuid library.
The amount of data is 100 million. And we measured record retrieval in milliseconds (switched on using \timing true;) by using their respective primary key. We pick 10 arbitrary records by taking them somewhere in the middle. A sequence of them are used to prevent query cache.
select * from uuid where counter = 50000000; -- 50 million
select * from uuid where counter = 50000001;
select * from uuid where counter = 50000002;
...
Then use them to query the records on our commodity hardware.
select * from uuid where id = '0187bf9d-6a93-7c42-873b-c566cee2d749'; -- and the next 9
select * from serial where id = 50000000; -- and 50000001, 50000002, ...
An average is calculated for each of the UUID and serial methods.
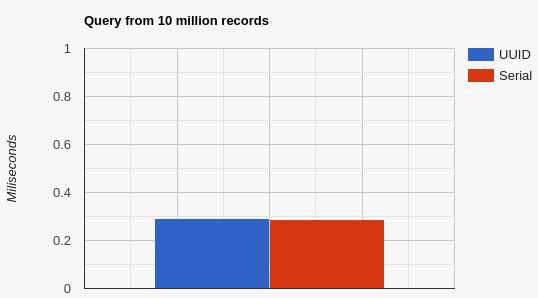 Figure 6: A query time benchmark of 10 separate
Figure 6: A query time benchmark of 10 separate SELECT from 10 million records
As you can see, both returns a sub-millisecond response at 0.292ms and 0.288ms for UUID and Serial method respectively. In the grand scheme of things, an average difference of ~4 microseconds is hardly material and falls within the margin of error.
Alternatives
UUID is not the only random-ish primary key you can use. Some alternatives are
ULID
- It is also 128 bits like UUID
- 48 bits of timestamp and 80 bit of randomness versus UUID V7 which has 12+62 bits for randomness. Example: 01ARZ3NDEKTSV4RRFFQ69G5FAV
- k-sortable
- 26 characters
- No conflict with ambiguous combinations of characters like O and 0 (zero) because it uses Crockford’s base32 for readability.
- Case-insensitive
- No dashes
- URL safe
- No sub millisecond precision unlike UUID V7
- Reason not to use: no RFC unlike UUID
KSUID
- From segment.io https://github.com/segmentio/ksuid
- Response to UUID V4 limitations
- has 160 bits = 32 bits of timestamp plus 128 bits of randomness
- Exceeds 128 bit so cannot use
uuidtype in database - Has 27 characters
- Entirely alphanumeric base52, no dashes. Example: 0ujsszwN8NRY24YaXiTIE2VWDTS
- Reason not to use: 160bits meaning cannot use existing uuid column type
MongoID
- 96 bit https://docs.mongodb.com/manual/reference/method/ObjectId/
- K-sortable
- Includes machine ID to prevent ID clashes
- Reason not to use: MongoDB
Conclusion
Using UUID or other k-sortable alternatives eliminates many problems with using serial ID for example sensitive data exposure to client. Randomness is bad for b-tree index but a leading time component makes it k-sortable and thus more index-friendly. Insert operations can be done concurrently and sharding becomes easier. However, the timestamp is visible to the clients.